

In our previous topic, we discussed the problem-solving task of AI. The algorithm is one of the main techniques of problem-solving. There are many types of algorithms in AI. Among them, some of the main categories can be discussed here.
An algorithm can be defined as a place where to start the programming process and an AI algorithm can be defined as an extended subset of machine learning that advises the computer to learn to operate its own. Artificial intelligence algorithms have been used to solve millions of problems so it is hard to list every single algorithm. So, let’s discuss the three main categories of artificial intelligence algorithms.
The technique of Categorizing data into classes is called classification. The main goal of classifying problems is to determine the category under which the problem falls. In AI, algorithms called classification algorithms are used to identify the category of the given dataset and these types of algorithms are used to predict the output for the decisive data. A classification algorithm is a supervised learning technique where the program learns from the observations and then classifies new observations into several groups. The classification process helps to segregate large quantities of data into separate values like 0/1, True/False. These algorithms are mainly used to predict the output of categorical data. Similarities of patterns like similar words, number sequence,s, etc can be found using this method.
Most widely–used classification algorithms:
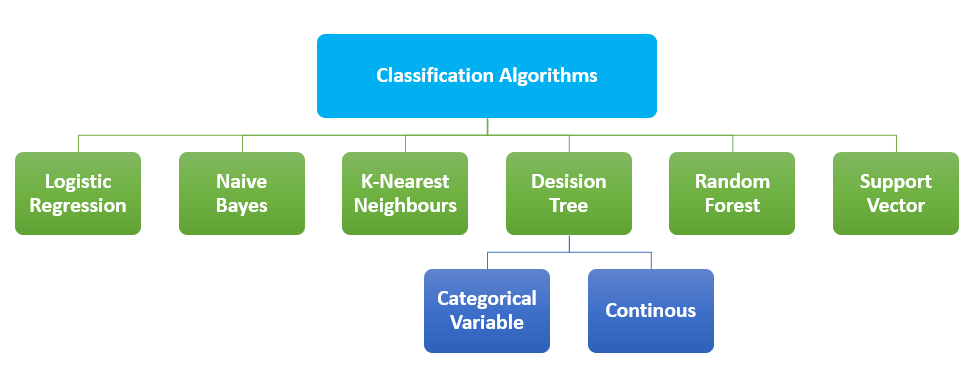
As it sounds like regression, it is used to classify samples and falls under the classification algorithm. The concept of predictive modeling as regression is used by this model. In logistic regression, Categorical dependent variables are predicted using a set of independent variables. The outcome of this algorithm is probabilistic values that come between 0 and 1. It can classify new data using discrete datasets. It is significant since it provides probabilities.
This algorithm is based on Baye’s theorem. It is the simplest solution but is powerful. This algorithm can be used for both binary and multiclass classification based on historical results. The accuracy of this algorithm depends on the strong assumptions. Baye’s theorem can be used to determine the impacts of the occurrence of an event on the probability of another event.
It is one of the simplest classification algorithms. KNN simply stores the occurrence of the training data rather than constructing a general internal model. Classification is based on the majority vote of K nearest neighbors of each point. After computing the distance between the given query and all the available examples in the data, a limited number of examples that are closest to the given query are selected. This number is represented by the letter K in the KNN algorithm. Then the most frequent label is voted. This is a simple description of the working of KNN. This can be grouped under for both classification and regression.
The decision tree method can be said as the most instinctive way to visualize a decision-making process. A decision will produce a sequence of rules that can be used to classify the given data. It builds classification models in the form of a tree structure. The given dataset is divided into smaller and smaller subsets. And the final result will be a tree structure with decision nodes and leaf nodes. The method starts from the root of the tree to predict the class of the given input. There are two types of decision trees based on the nature of the target variable
One of the main problems with Decision Tree is that it may lead to overfitting
It uses several decision trees on various subsamples of datasets. For combatting overfitting and to improve the predictive accuracy, the method takes the average result as the model’s prediction. With the accuracy of the results, it can be used to solve complex problems. The implementation of this method is somehow difficult and also requires more time to form a prediction.
To classify the data points, the Support vector machine uses a hyperplane in an N-dimensional space. The number of features is represented using N here. N can be any number but with a larger number, it is harder to implement a model. If N=2 then we can assume the hyper line as a line that separates the tags. This line can be considered as the decision boundary. Anything that falls on different sides of the hyperplane is assigned to different classes.
| ALGORITHM | ADVANTAGES | DISADVANTAGES |
|---|---|---|
| Logistic Regression |
|
|
| Naïve Bayes |
|
|
| K-Nearest Neighbors |
|
|
| Decision Tree |
|
|
| Random Forest |
|
|
| Support Vector Machine |
|
|
The process of dividing the data points into several groups is called clustering. The data points in each group are similar to each other and dissimilar to the data points in other groups. Similar items are grouped. The most common clustering algorithms are:
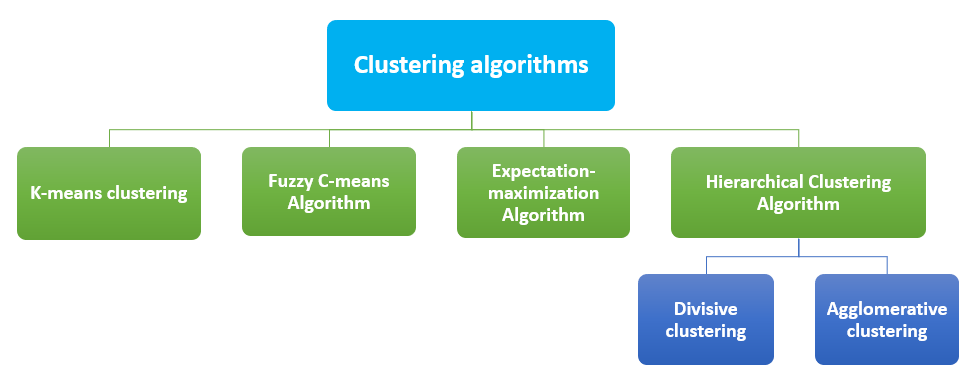
This is the simplest learning method. In AI, K-Means groups data into clusters to study the similarities. The data points are grouped into K numbers of clusters. For each cluster, a centroid is calculated and then the distance between the centroid of the cluster and the data point is evaluated.
Probability is the basic working principle of FCM. This method is called fuzzy because it doesn’t assign any absolute membership to any data point over any particular cluster. Each data point is assigned with a probability value for belonging to any cluster.
Gaussian distribution is the working principle of this method. Random values are selected for the missing data points and with those guesses, the second set of data is estimated. These new values can be used to create a better guess for the first set and the procedure will continue until the algorithm meets a fixed point.
Similar objects are grouped into clusters in this model. The endpoints are a set of clusters where each cluster is distinct from other clusters and each cluster is with objects which are broadly similar to each other. Two types of Hierarchical Clustering Algorithm are
| Algorithm | Advantage | Disadvantage |
|---|---|---|
| K-Means Algorithm |
|
|
| Fuzzy C-means Algorithm |
|
|
| Expectation-Maximization Algorithm |
|
|
| Hierarchical Clustering Algorithm |
|
|
Regression Algorithms are mainly used for predictions. Regression in AI can be defined as the mathematical approach to finding out the relationship between variables. The output of the regression model is numeric values. The common regression algorithms are:
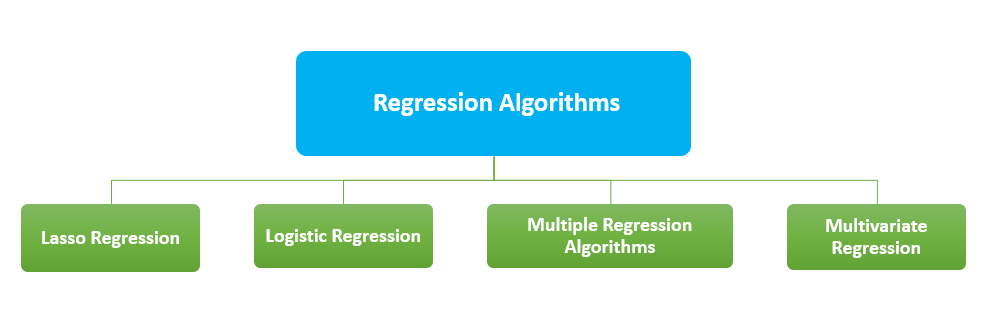
Lasso regression is a method that uses shrinkage. LASSO stands for “Least Absolute Shrinkage and Selection Operator”. By imposing limitations on data points and shrinking some of them to zero value the algorithm obtains a subset of predictors. This subset is in a way that minimizes prediction error for a response variable.
The main application of this method is for binary classification. A set of variables are analyzed and predicts a categorical outcome.
It takes multiple explanatory variables as inputs. It can be described as a combination of linear regression and non-linear regression algorithms. The relationship between the dependent variable and several predictor variables can be assessed using multiple regressions.
This algorithm is operated with multiple predictor variables. It is an extension of multiple regressions. This algorithm is mainly applied with retail sector product recommendation engines.
| Algorithm | Advantages | Disadvantages |
|---|---|---|
| Lasso regression | Simpler and more interpretable models | Not for group selection |
| Logistic regression | Easier to implement. Less prone to overfitting | Nonlinear problems can’t be solved. Difficult to capture complex relationships. |
| Multiple regression | Accurate than simple regression. Ability to identify anomalies. | Use incomplete data and falsely conclude that a correlation is a cause. |
| Multivariate regression | Help us to understand the relationship among variables in the data set. | Not suitable for smaller datasets. |
Algorithms have their advantages and disadvantages in terms of their implementation, accuracy, performance, and processing time. The above are just a few algorithms and a little about them. If you want to know more about these please visit our tutorial on machine learning.

