

In AI, the universal technique for problem-solving is searching. For a given problem, it is needed to think of all possible ways to attain the existing goal state from its initial state. Searching in AI can be defined as a process of finding the solution for a given set of problems. A searching strategy is used to specify which path is to be selected to reach the solution.
There are four essential properties for search algorithms to compare the efficiencies.
Search algorithms can be classified mainly into two based on the search problems;
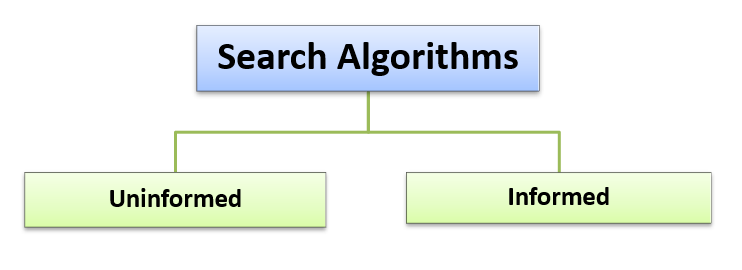
The uninformed search algorithms are unaware of the domain knowledge like the closeness, the goal location. It only knows how to traverse and how to distinguish between a leaf node and goal node and hence it is operated in a brute-force way and so it is also called brute-force algorithms. It searches every node without any prior knowledge and is hence also called blind search algorithms.
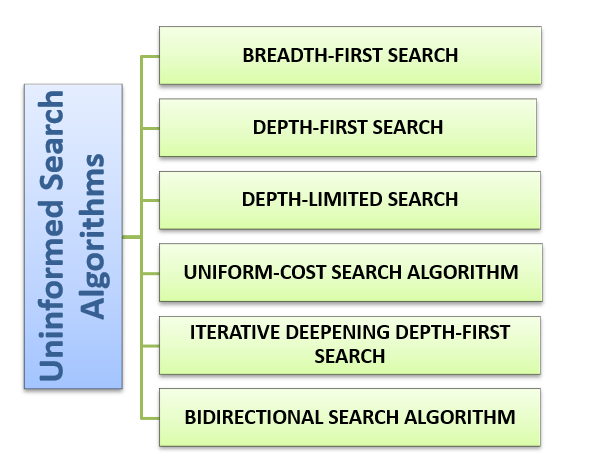
Uninformed search algorithms can be divided into six main types:
It is the most common searching strategy to traverse a tree or a graph. It uses a breadthwise searching procedure and hence it is called breadth-first search. The process starts from the root node of the tree and expands to all the successor nodes at the first level before moving to the next level nodes. The queue data structure that works on the First In First Out (FIFO) concept is used to implement this method. As it returns a solution (if it exists) it can be said as a complete algorithm.
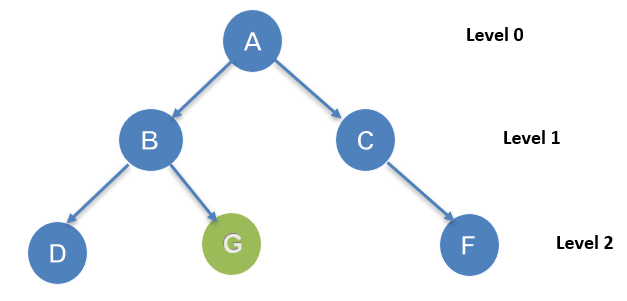
The searching procedure starts from the root node A. Here the goal node is G. from node A it will traverse in an order of A-B-C-D-G. it will traverse level-wise.
| Advantages | Disadvantages |
|---|---|
|
|
It is a process similar to that of BFS. The searching procedure starts from the root node and follows each path to the greatest depth and then backtracks before entering the next path. The stack data structure that works on the concept of Last In First Out (LIFO) is used to implement the procedure.
Example:
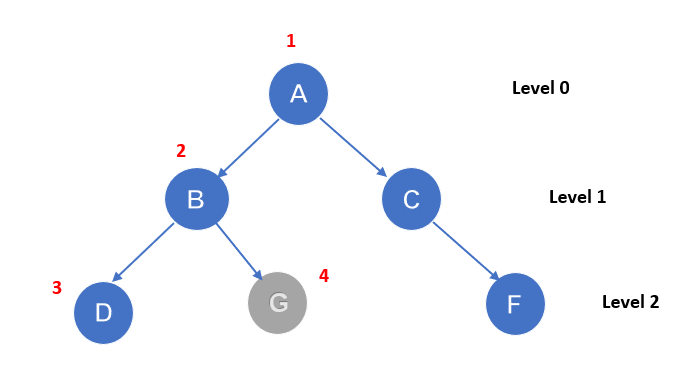
The searching procedure starts from the root node A. Here the goal node is G. From node A it will traverse in an order of A-B-D-G. it will traverse depth-wise.
| Advantage | Disadvantage |
|---|---|
|
|
It is much similar to a depth-first search with a predetermined limit. The main disadvantage of DFS is the infinite path, this can be solved with a Depth-limited search. Here the node at the limit is treated like it has no successor nodes further. It can be called an extended and refined version of DFS.
Depth-limited search will terminate with two conditions.
Example :
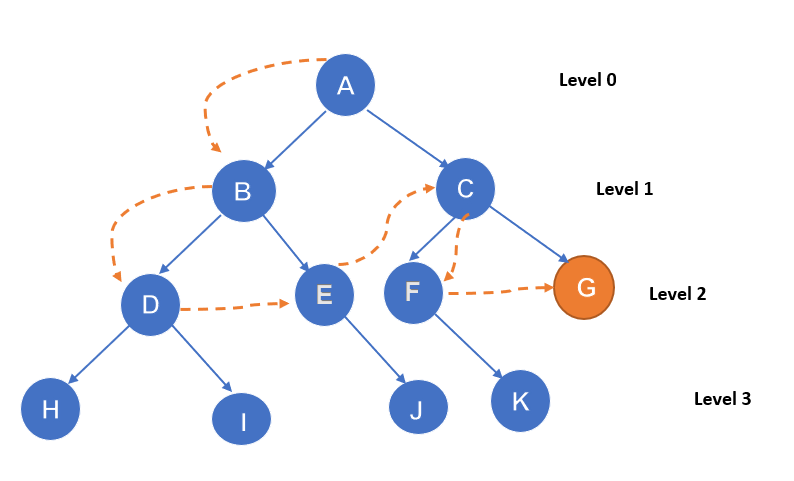
The searching starts from node A. The limit for the procedure is set as l=2. Our goal state is node G. The process is like A-B-D-E-C-F-G.
| Advantage | Disadvantage |
|---|---|
|
|
It is used to traverse a weighted tree or graph. It is different from both DFS and BFS. Here the cost is considered as factor. There is more than one path to reach the goal. The path with the least cost is selected. For traversing the path an increased order of cost is selected. If the cost is the same for each transition then it can be said to be similar to that of BFS.
Example.
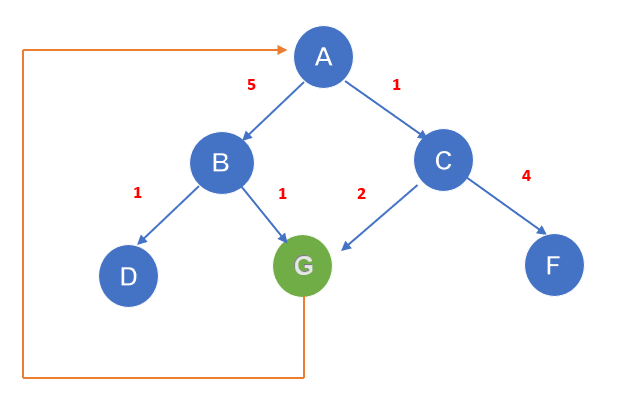
If the starting node is A and the goal to reach is G, then it will traverse A-C-G. The cost will be 3
| Advantage | Disadvantage |
|---|---|
|
|
It is a combination of both DFS and BFS. It will find the best depth limit and the limit is gradually increased until a goal is found. The algorithm performs a depth-first search to a certain depth limit and this depth limit is increased after each iteration until the goal is reached. The fastness of BFs and the memory efficiency of DFS are combined within this iterative deepening depth-first search. With large search space and unknown depth of the goal node, this can be more useful.
Example:
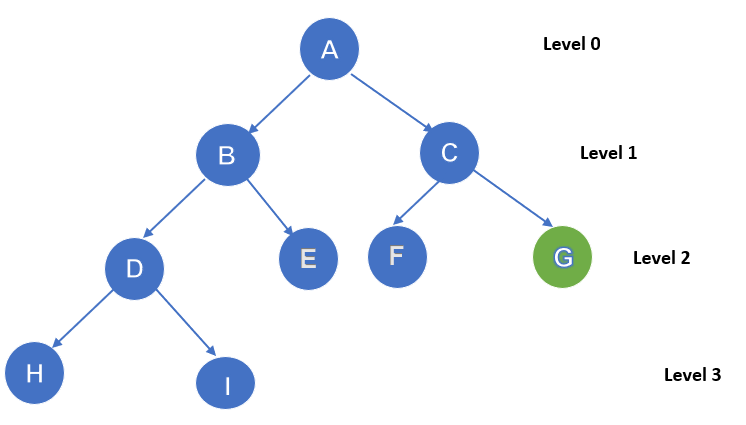
1’st Iteration------A
2’nd Iteration------A,B,C
3’rd Iteration------A,B,D,E,C,F,G
4’th Iteration------A,B,D,H,I,E,C,F,K,G
The goal node is found at the 4th iteration.
| Advantage | Disadvantage |
|---|---|
|
|
It performs two searches simultaneously. One from the starting end is called forward-search and the other from the end is called backward search. One single graph is replaced with two small subgraphs one from the initial vertex and the other from the final vertex. The searching procedure stops when these two graphs intersect each other. It can use search techniques such as BFS, DFS, DLS, etc.
Example:
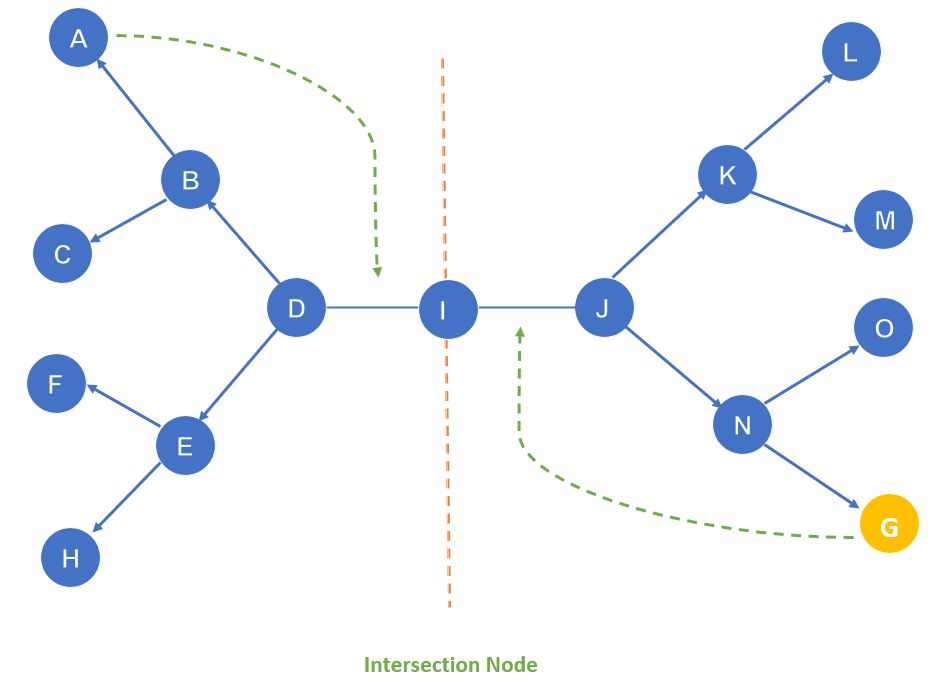
The algorithm terminates at node I where the two sub-graphs meet.
| Advantage | Disadvantage |
|---|---|
|
|

