

In this tutorial, we are going to discuss the entire life cycle of data science. It's all about how to execute the data or the assigned project.
The Data science life cycle is a kind of framework that provides some information or steps about how to develop a data science project. It mainly contains some steps that should be followed by the data scientist when they begin a project and continue until the end of the project. These steps are not fixed and they can be bypassed or can be repeated until we get a corrector satisfied results. According to the project sometimes it may take a few months to complete because this is a lengthy procedure.
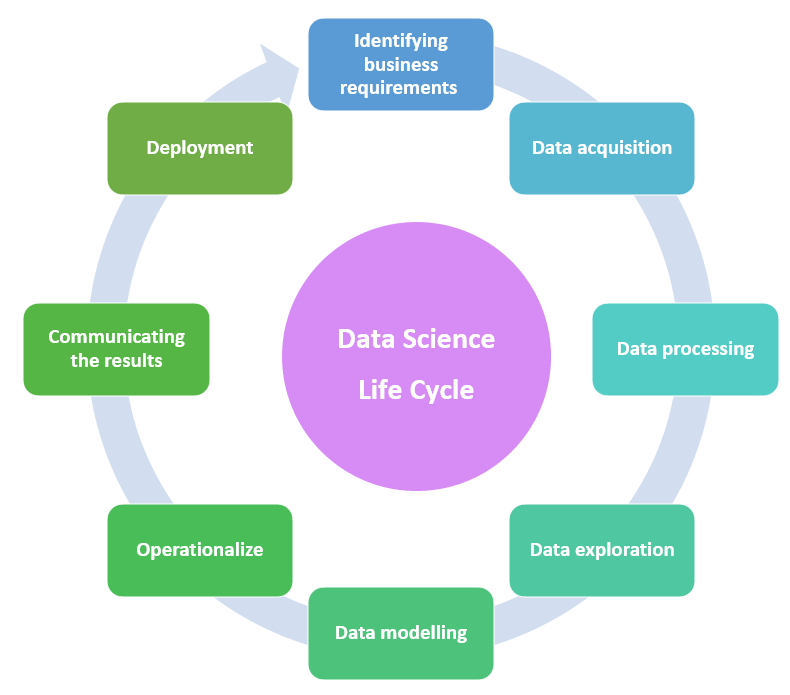
This is the very first step in the data science life cycle. Gathering all the information from the available data sources Identifying the problem and finding out the objectives are the main two things done in this step.
Before starting a project first we should have a clear idea about what are the project requirements, what is the need of the clients, and market trends. Everything should be identified clearly to get better results.
How do identify the business requirements?
Collecting data from multiple sources means, here the data scientists gather information from different sources like databases, APIS, webpage, online repositories, etc. Needed information should be collected from the available sources. In order to read data from specific sources, some special packages like R or Python are available. Many precious data are also gathered from social media like youtube, Twitter, Facebook, etc.
Gathering data from files is known as the conventional way of data gathering. The main 5 methods to collect information are by conducting surveys as well as questionnaires, the 2nd method is by conducting interviews where data is collected directly from the respondents by asking questions to them, the 3rd one is data collection from group discussions, 4th method is direct observation and final method is gathering information from documents. These are the 5 main methods used to gather information.
Cleaning of data and transformation of data is done in this step.
The obtained data will not be clean so before moving to the next step it is needed to process the data which means raw data which is obtained from different sources should be cleaned. The cleaning of raw data is done by scrubbing and filtering. While cleaning the data if we are noticing any missing data sets proper replacement should be done. This means replacing and withdrawing values are also done while cleaning the raw data.
Understand different patterns from the data which is cleaned and useful insights are retrieved from that. Before using the data it should be examined. Why this is done because data may contain different types of data like numerical data, ordinal data, nominal data, as well as categorical data. Different data types should be handled in a different manner so only proper examination of data will help to identify different data types.
In order to understand different patterns data scientists can use histograms, Microsoft Excel spreadsheets, etc.
In data modeling, a model is created which predicts the target most accurately and the model which is created is evaluated and tested in order to check the efficiency. Various tools used in model planning are R, python MATLAB, and SAS.
Mainly there are two types of data models and they are conceptual data models and physical data models. The concepts of database and the existing relationship between them are represented visually in the conceptual data model and this model contains entities/subtypes, attributes, relationships, and integrity rules. After the conceptual data modeling, the next step in action is the physical data model. That means each data entity's attributes are clearly defined here. The physical data model consists of tables, columns, keys, and triggers. The data modeling contains many diagrams, symbols or text these are mainly to represent the data based on how it interrelates.
The model which is chosen in the above step is checked in this stage which means it will run the model to understand how it works. After running the model findings based on its performance are documented and final reports are submitted. The final report consists of all the necessary briefings, code details, performance details, and technical information. If their findings are perfect then it is ready to use and the team will also deliver the final reports, code as well as technical documents in this stage.
In this stage, the project results and valuable findings can be communicated to the responsible people. Here they can compare it with the initial stage where we identified the problem with our findings, in order to check whether useful insights are given by the data.
After the discussion, if the quality of the result needs an improvement or any fault is detected then again we have to start from the very first step. If no mistakes are found and the higher authority is happy with the data scientists and his team’s work then we can move to the last step.
Deployment is the final step of a data lifecycle. The main goal of this stage is to deploy the model into a production environment. Validating the performance of the models is done by the users. Monitoring the performance of the model is done very carefully and if any changes are needed that is also done in this stage. Continuous monitoring will be done because data trends are changing day by day so according to that we should make some changes to the model mainly to adjust to new evolving trends and to avoid performance regression.

