

We found that logistic regression is a useful algorithm for binary classification by mapping the linear relationship between the log odds of a class and the data. However, logistic regression is still limited by linear assumptions.
In this tutorial, we’ll discuss discriminant functions: functions that try to identify which combination of variables can separate out multiple classes.
Logistic regression is a strong and powerful classification algorithm that comes under supervised learning. But it has some limitations that made the formation of LDA and other algorithms
LDA solves these problems and can be used instead of logistic regression if there are any of these conditions. IT will be good if you try both and select the best one.
Linear discriminant analysis(LDA) is a method, which is used to reduce dimensionality, which is commonly used in classification problems in supervised machine learning. It is used for projecting the differences in classes. In simple words, we can say that it is used to show the features of a group in higher dimensions to the lower dimensions.
Suppose we have two groups of different data with different features and we want to separate them or classify them using a single feature. When we are doing so, there may be a high chance of overlapping as shown in the picture. So we have to increase the number of features for having a good classification.

Consider an example for making the concept more clear. Let us have two set of data which are of different groups. Now we want to categorize them into two different groups as in the 2D picture. But when we try to make the data points in a 2D graph, there will not be a linear line to separate the data into two groups.
In such cases we uses the linear discriminant analysis that reduce the 2D graph in to single dimension graph so we get more seperatability between the data points in two groups.
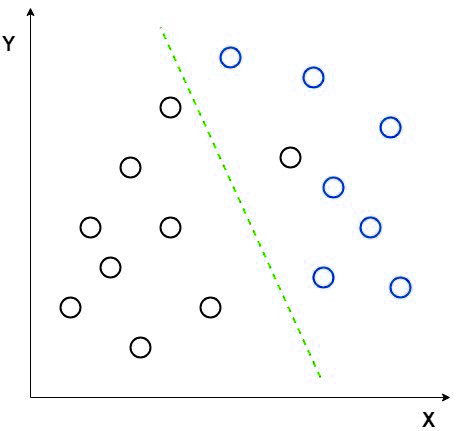
In this method, the LDA is using the graph coordinates such as X-axis and Y-axis to create a new coordinate and show the data using the new coordinate or axis. So we achieve the single dimension reduction from a 2D graph and helps to increase the separation.
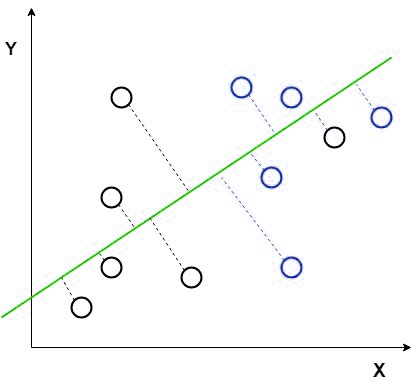
The new cordinate is made using two rules that are
In the above picture we shown the new axis in red color and we have plotted the data points with respect to new axis such that the distance between the mean of two group is increased and the variance between the two groups are reduced.
After plotting the datapoints using our rules on the new axis it will be like this as in the below picture.

The function above is the discriminant function, which tells us how likely a data point belongs to class k. Note that πk is the prior for class k and that fk is the probability density function of the data for class k.
For LDA, we’ll assume that the data is a Normal distribution with a mean μk. We’ll also assume that the covariance matrix Σ is the same across all classes. Thus, we obtain the following discriminant function:
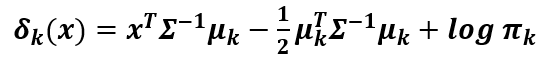
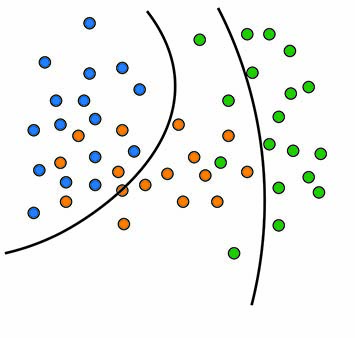
The main point is this: if we compare any two classes, the line that best separates the two classes is a linear function. Thus, LDA finds the best lines that separate any two classes.
We can’t able to use this linear discriminant analysis all time as it will get fail if the mean is shared as the LDA can’t able to find the new coordinate and the axis. In that case, we use nonlinear discriminant. Some popular examples for the nonlinear discriminant are
Now, what if we wanted to find curves that can separate more non-linear data? To do this more complex task, we need to determine and consider the differences in variances for each class.
If we don’t assume that the variance is the same for each class, the discriminant function becomes more complex:
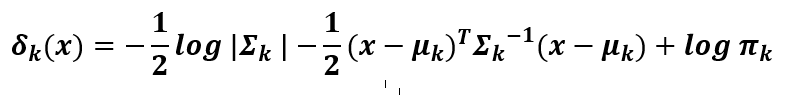
The takeaway is that by not assuming equal variance, the discriminant function becomes a quadratic function. This allows us to separate non-linear data with unequal variances.
Discriminant analysis is useful for classifying data using linear and nonlinear decision boundaries, but there are specific cases where you would want to use one algorithm over another.
The following table describes use-cases for choosing between linear and quadratic discriminant analysis.
| LDA | QDA | |
|---|---|---|
| # of observations | Low | High |
| # of features | High | Low |
| Data distribution | Normal | Nonlinear |

