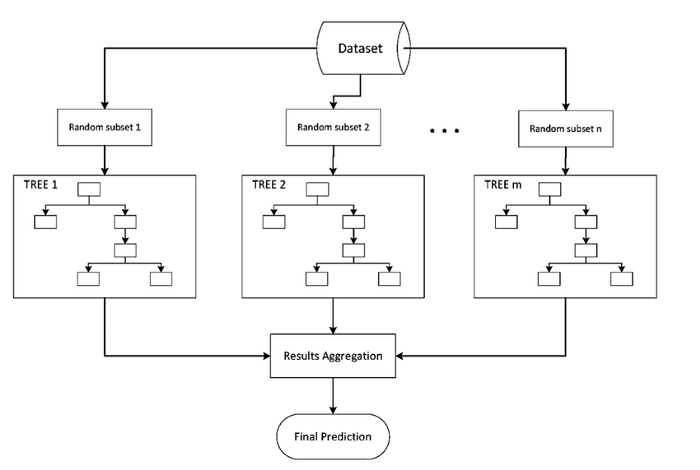
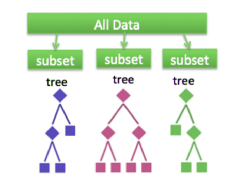
So far, we have been discussing individual machine learning algorithms that, alone, have practical applications extending to simple real-world problems. However, when datasets become much more complex and large, simple machine learning algorithms begin to break down because the assumptions we impose on the model do not hold true for real and dynamic data.
This tutorial covers ensemble learning algorithms, a family of machine learning algorithms that address this big real-life data problem by combining multiple models together to make an optimum model get accurate predictions.
Now let us consider an example to make the concept more clear. Consider a decision tree for understanding the concept of ensemble learning. Here we need a predicted result based on the input questions we feed into the model.
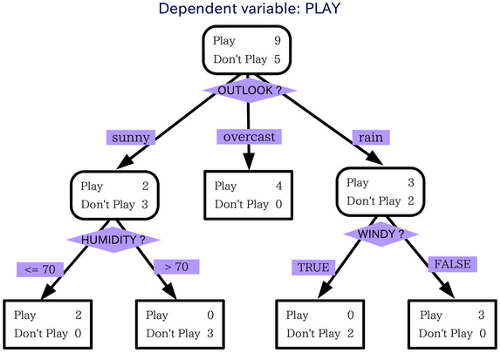
In this example we consider the question: can we go out in the rain? For that, the decision tree takes a lot of factors and it makes a decision or asks another question for each factor. So when we check the above image you can understand that if the situation is overcast we can go outside.
If the situation is rainy we have to ask if it is rain with wind or not. If it is windy, we can't go out, else we can go out. Similarly, when it is sunny we have to ask if the humidity is high or not. And make decisions according to that.
If we are using the ensemble method things are handier. Ensemble methods give the freedom to take a small model of the decision tree and calculate the features to select and what questions to ask in every split of decisions.
Ensemble learning algorithms combine multiple algorithms to solve a complex problem. They are analogous to a company, which consists of experts that are good at what they do in order to solve a complex real-world problem. Combining algorithms in a strategic fashion can have much better performance than individual regressors or classifiers.
However, it is important to note that not all ensemble approaches will outperform a simple well-trained model. Rather, we can think of an ensemble learning model as a risk mitigation strategy. Instead of settling with a poorly-trained model, we can combine the results of several different regressors and classifiers to have, at least, a decent performing model.
It is important to note that the predictions resulting from many kinds of machine learning algorithms are dependent on initial starting conditions. For example, K-means clustering depends on the number of clusters and where those centroids are initialized.
In any given iteration, the predictions from these models can change, even when we keep hyperparameter values constant. This is known as model stability, and it is important to have a model that is robust against these different initial conditions.
Ensemble methods tend to give stable model forecasts and predictions. This is because the model outputs are combined, typically by averaging the results from several regressors or taking the majority vote across different classifiers. The more models that are generated, the more stable the value tends to be due to the law of large numbers.
Ensemble models combine different models with different assumptions and hyperparameters. Thus, they can capture more of the variance that exists within the dataset. This means that they can identify more non-linear trends within the data, compared to a simpler model.
One major weakness of ensemble learning models is that because they are more complex, they become like black boxes - it becomes harder to identify sources of model error and how the model comes up with a conclusion.
Because ensemble models capture more of the data variance, they are more prone to noise in the data and overfitting. One method to mitigate this issue would be to apply regularization techniques and sample appropriate hyperparameters that can best capture the data trends.
However, we’ll also discuss algorithm-specific approaches that solve this issue of model overfitting in the coming tutorials.