

From the previous tutorial, we went over a pretty powerful method to model variables using linear regression. However, linear regression models are highly susceptible to noise. This tutorial will cover strategies to de-noise the dataset and improve the performance of linear models.
When we're given a new dataset, we may find that there are highly correlated features with each other during exploratory data analysis. Additionally, we may also find that uninformative features may not separate two classes from each other or identify features with low variance. If the unimportant features are there it will negatively affect the accuracy of our system, increase the complexity of the model.
If we can, we should get rid of these features. This process of removing redundant or uninformative features from the data set for making a good system is known as feature selection. Feature selection is advantageous because:
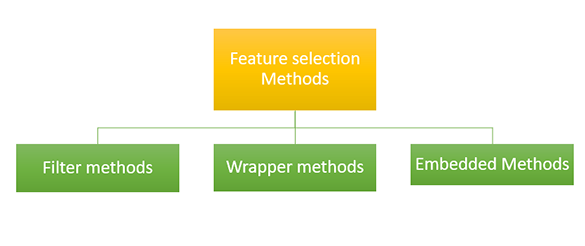
There are several strategies to perform feature selection, they are
Filter methods can be used to select the features without thinking of the machine learning algorithm. Filtering is done in the preprocessing step of machine learning implementation. The filtering method is an effective and cheap process to remove duplicates, correlated and redundant data. The filtering method is not much effective in dealing with the multi-collinearity data because in the filtering method selection is done individually on each data and it will be tough if the input data is related to each other.

Filtering uses these techniques
Information gain can be defined as how much information can a feature provide for the target prediction and to reduce the error in the prediction. The information gain of each input attribute depends on the target values.
This test is used in categorical values, it is used to find the relation between the values by comparing the observed values with expected values.
In this method, we are giving a score to each attribute using fisher criteria. Then it selects the attributes, which have the larger fisher value, which must be the best-selected feature. Finally, we get a good set of features.
In this method, we are removing the input features in which its variance does not meet some threshold value. In this method, what we assume is the high variance value indicates the input features contain information that is more productive.
In this method, we are using the mean value and then we find the difference from the mean value. The process is similar to the variance threshold method, but using the mean and its difference.
This method is used when the two input variables are dependent. In that case, we observe how much information of one variable we can collect by using the other variable. It measures how much a feature is giving to predict the output.
In this method, we are measuring the quality of an attribute that is selected randomly from a dataset.
We'll describe wrapper methods - methods that try to train models on subsets of data. Based on the model's performance, we decide to add or remove features, then we see if the new model outperforms the old model.
The main advantages of wrapper methods are they can able to provide the best set of features for the algorithm for training. It can provide more accuracy and efficiency but at expense of more computational power.

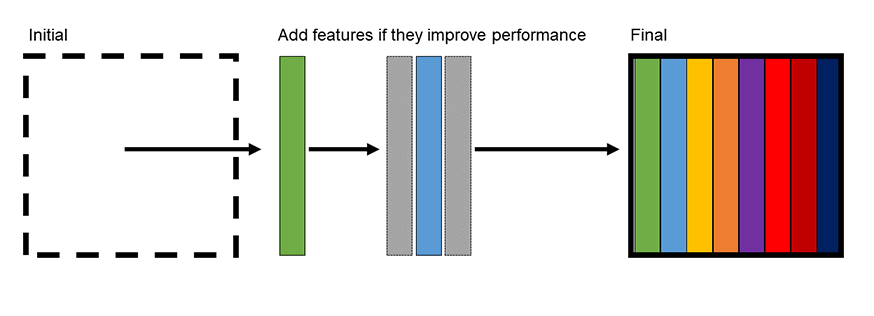
Forward selection is where we start by having no feature being modeled. Then, we iteratively add a feature into the model and see whether or not the feature improves model performance. Performance can be measured by several metrics, including the mean-squared error or coefficient of determination.
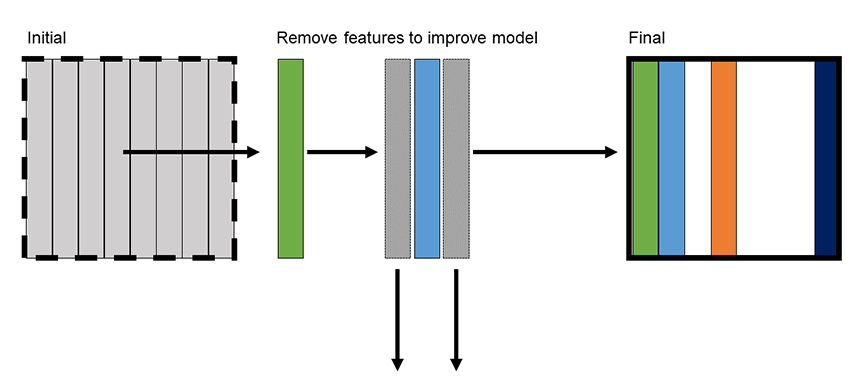
Backward elimination is where we start by modeling all the features in the dataset. Then, we iteratively remove features that have no impact on the model or features that, when removed, improve model performance.
Forward selection is where we start by having no feature being modeled. Then, we iteratively add a feature into the model and see whether or not the feature improves model performance. Performance can be measured by several metrics, including the mean-squared error or coefficient of determination.
Stepwise regression combines the best of both forward selection and backward elimination. By combining both methods, we eliminate uninformative features while re-introducing features that may have been thrown out prematurely.
The scikit-learn library has several methods to perform feature selection primarily through elimination methods. The documentation for feature selection can be found here.
In embedded methods, we are using the feature selection algorithm as a part of the machine learning algorithm so in this method, we can overcome the disadvantages of the filter methods and the wrapper methods. In this method, we can also able to merge the qualities of the filter method like fast and easy with the quality of wrapper methods such as accuracy and efficiency.
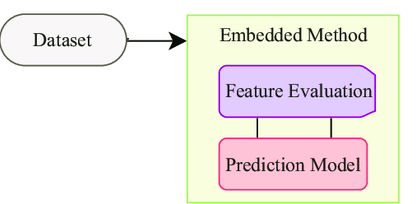
Some of the embedded techniques are
In this method, we are using the penalties for the input variables to avoid the overfitting of the model. We already know we use this regularization in lasso as L1 and L2 regularization. Here we are adding a penalty for the coefficients to bring some to zero and eliminate them from the dataset.
here we check which factors have an impact on the predicted output that we call it to feature importance we use this method in the random forest method. We use the feature importance for selecting the

