

In machine learning, we are interested in finding a function that best maps the relationship between some data and an outcome. We are usually interested in how accurate the model predictions are compared to the actual label or data value. To do that, we need to set a procedure to maximize the probability of a given class or minimize the model error. This is known as an optimization problem.
For the remainder of this tutorial, we’ll discuss the most common usage of optimization, which is to minimize the model error or cost value. Functions that compute the model error are known as cost functions.
A cost function tells the model how wrong the model is in mapping the relationship between the input data and the output. This is measured using a single value called the cost value representing the average error between the predicted and actual values.
Now that we have a means of measuring the model error, we need to discuss how the cost function is minimized. The optimization procedure we’ll use is called gradient descent, a highly efficient optimization algorithm used in several models such as neural networks. This algorithm attempts to find the minimum error associated with a given model.
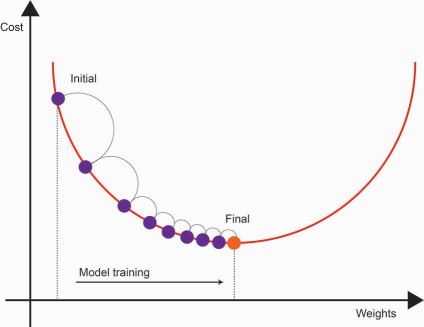
Mode training occurs over several iterations in a stepwise manner. Intuitively, gradient descent attempts to find the direction the model should tweak its coefficients to reduce the errors during each step. This direction is known as a gradient.
As we continue training the model through each iteration, the cost value gradually converges to a minimum. At this point, the cost value stabilizes. During each step, the model coefficients are tuned by the gradient, such that it minimizes the cost function.
Now that we’ve discussed why we need to compute the cost value, we’ll discuss some common cost functions.
The mean-squared error (MSE) is a relatively intuitive function that estimates the average squared of the errors. The square term forces values to be positive, where values closer to 0 indicate less model error. This cost function is typically applied in regression-based tasks.
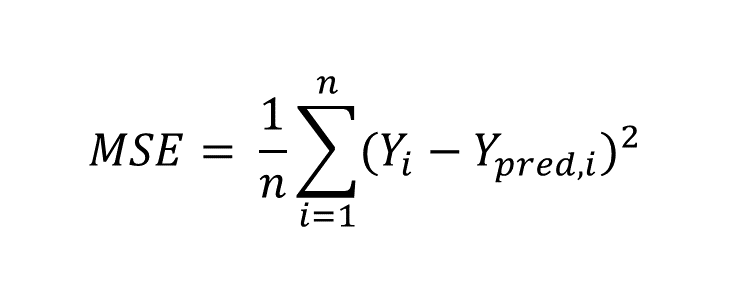
Cross-entropy is the cost function typically applied in classification tasks and has roots in logistic regression. Cross entropy is derived from information theory and measures how different two probability distributions are for a random variable.

If we extrapolate this to be a binary classification problem, the average cross-entropy expression will look like the following:
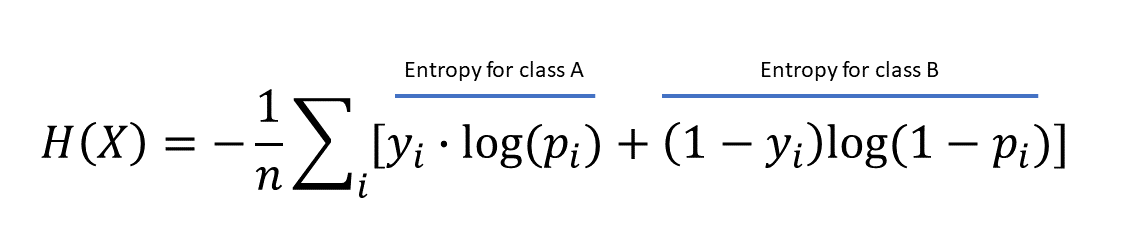
The interpretation for the cross-entropy loss value is the following. If the value is 0, the predicted class probabilities are perfectly identical to the actual set. However, if the value is higher, there is some distance between the probability distribution between the predicted labels and actual data.
The example above is a binary classification equation for the cross-entropy loss function. However, what if there are more than 2 classes?
Without getting into too many technical details at the moment, we can generalize the loss function above to consider a multi-class logistic regression problem. The softmax function is an extension of multinomial logistic regression (which will be covered more later). Still, it uses the same cross-entropy loss function to evaluate the probability an observation belongs to a given class.

