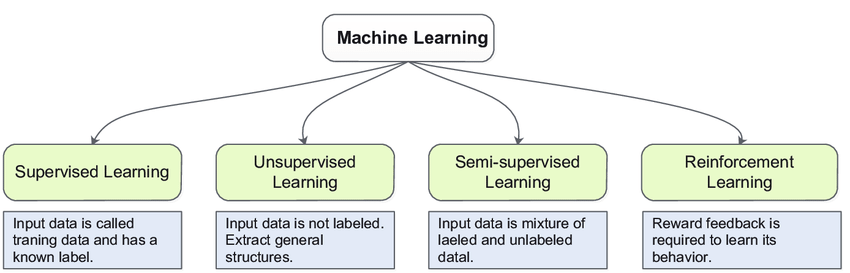
Machine learning is a process that helps the computer to learn from the data and that will help the machines to make decisions on their own that is machine learning is helpful for the development of Artificial intelligence AI.
Each machine learning algorithm solves different types of problems. We have to select the Machine learning model depends on the outcome we expect and the data we are providing. In this machine-learning tutorial, we will cover all the machine learning models.
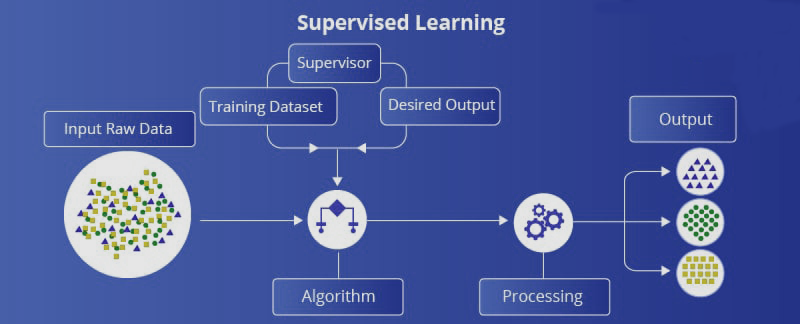
Supervised learning is a kind of ML in which we provide sample training data to the machine learning system for the train it. The ML will predict the output with respect to the sample data we have provided.
Let’s say we want to predict housing prices in the next month, given house prices from previous years. This is an example of supervised learning. We are trying to learn a function or model that relates the input dataset with an outcome.
Here system creates a model using the sample data for understanding and learns the data and dataset and from that provide an outcome.
Supervised learning is done under supervision which is similar to the classroom where students doing their activities under a supervisor. Example for supervised learning is Spam filer, house price prediction, face recognition, etc.
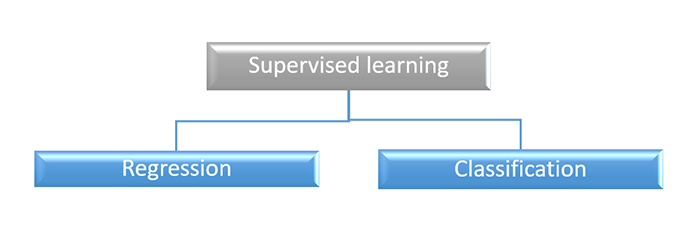
Supervised learning performs two kinds of tasks:
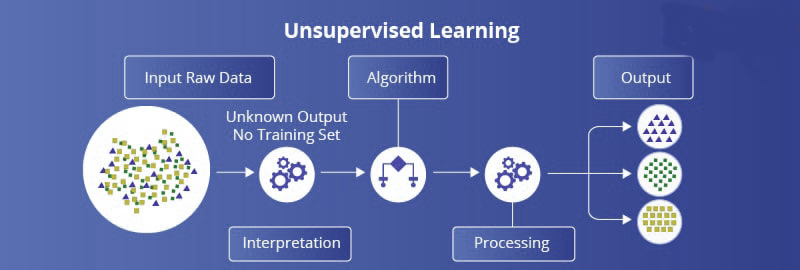
Unsupervised learning It is the direct opposite of supervised learning which means machine learning is done without any supervision. Looks at a dataset and tries to find the best underlying representation of the data.
There are no labels or numerical values to predict. Instead, the algorithm learns the data distribution to reveal structures within the dataset. The analyst (you) must interpret these structures and associate them with some meaning.
In unsupervised learning, we are providing the data without any relation and the algorithm work with the data to find some related patterns from the data without any supervision. Here algorithm has to find out the relation from the huge amount of raw data.
Unsupervised learning is further classified into two
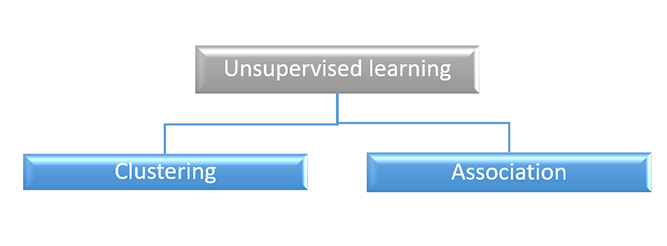
Unsupervised learning performs the following tasks:
In the above two algorithms, either we are providing all the labeled data and the model is using the labeled data and predicts the output or there is no labeled data at all and the model has to find the relation and pattern from the data.
Semi supervised learning stands in between two that means we have some labeled data but can't able to provide the labeled data for all the dataset because of the large cost.
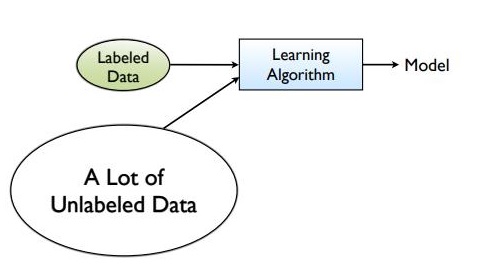
In real-world applications, we have a large amount of input data but very few labeled data. Semi-supervised learning attempts to use the best of unsupervised and supervised learning.
In semi-supervised learning, unsupervised learning groups unlabeled data into clusters. The user can label those clusters and feed the data into a supervised learning algorithm.
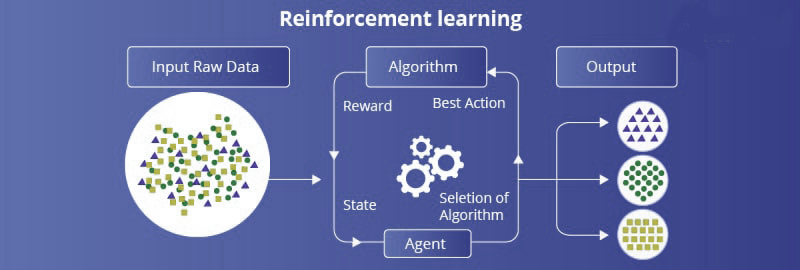
Reinforcement learning is the process of teaching an algorithm to come up with decisions. It is a feedback-based system. The user provides rewards and punishments for right and wrong decisions in the given task. The reinforcement-learning algorithm tries to get more rewards to achieve more accuracy and learn by interacting with the environment.
Reinforcement learning is another emerging technology that we associated with Artificial Intelligence.
The choice of the algorithm starts with the amount of data there is, and the data types within the dataset. If the goal is to perform a classification task and categorize data within the dataset, that prevents us from using regression-based algorithms like linear regression and LASSO.
Another general tip machine learning practitioners use to select algorithms is by evaluating how many data points there are versus the number of variables we are considering. If there are a small number of data points and a higher number of variables, linear-based models tend to work better. However, if there are many data points and a smaller number of variables, non-linear models are more appropriate.
In general, real-world data tends to have several data types in a single dataset (e.g., numerical, categorical, etc.) and are usually big high-dimensional time-course datasets.
In general, our goal is to use the most appropriate algorithm that can provide the best model of the relationships between the input data and some outcome or how to best group similar data points together. If we can do this with a straight line, linear algorithms tend to perform well.
However, when the data does not have these linear relationships or cannot separate data by straight lines, we should use non-linear algorithms. In general, real-world data tends to be more non-linear.
As discussed earlier, the more non-linear the algorithm becomes, the less interpretable it is. While non-linear algorithms tend to perform a lot better with non-linear data, sometimes we need to select less accurate algorithms that are more interpretable.
One area where this is evident is in the healthcare industry. Identifying sources of error is essential for a clinician to believe what the model is trying to predict because clinicians can be held liable for malpractice. Thus, if the model is easy to interpret and can relieve a pain point (e.g., higher accuracy, less labor, etc.), it will be accepted over a black-box model.
Training time is crucial when deploying machine learning algorithms at a production level. In general, the longer the training time, the more costs are associated with the model. These costs come from computational resources allocated to model training and its lag to ship out the model out in the market.
In general, the simpler the model, the faster it takes to train a model. However, more complex models tend to work better with real-world data because of their non-linear nature. Thus, the user or the company must decide what model is the most appropriate and understand the tradeoffs between cost and performance.
There are 6 general families of machine learning methods we can group algorithms into: