

There are some data points in real-world data that tend to look "different" than other data points. Outliers are data points that are mistakes - they are anomalies that are not representative of the data. In simple words, we can define an outlier as an odd one out in the data points. It shows different characteristics than the crowd data.
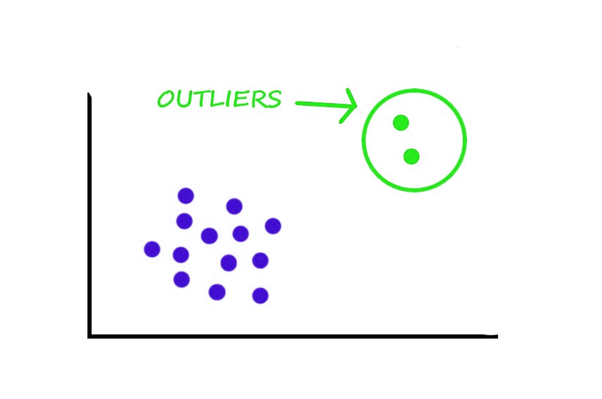
An outlier will be formed due to some execution error, incorrect entry, error reporting in observations, sampling errors, etc and it deviates us from the rest of the data points.
If possible, We have to remove the outlier data to reduce the error and improve the accuracy of the dataset but that is not an easy process. for that we have to analyze the outlier data which is commonly called as outlier mining or outlier analysis. Data scientists check the impact of outliers in data processing before caring about it.
Not all strange data points are outliers. Datapoints can have high leverage if they are extreme but describe an underlying natural phenomenon.
As a data scientist, it is essential to distinguish between data points that are outliers and those with high leverage. We'll cover some simple heuristic strategies to identify outliers.
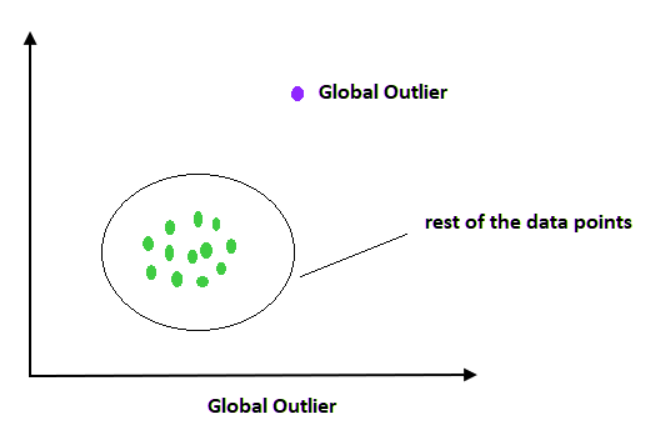
If the outlier data has so much different from the remaining data in the total dataset where this outlier is found is called the global outliers. For example, consider the age of some employees in an office and you found one with an age of 1000 which will be considered as global or point outlier data.
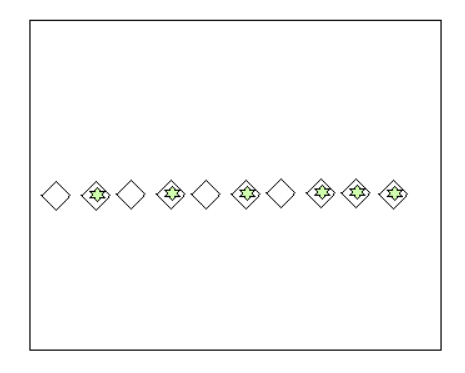
In a context, a data point value that has a large difference from the normal data points of that context dataset is called contextual outliers which means this data may not be an outlier when the context dataset changes.
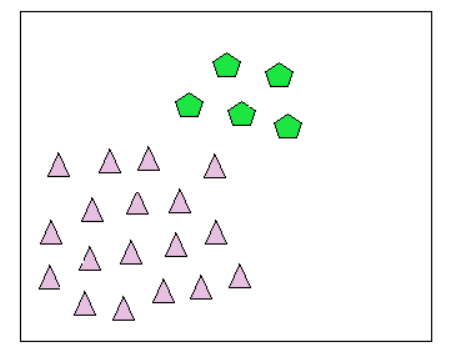
As the name suggests we have got some data points that have deviation or anomalous but we have a lot of data points close to each other with the same or similar anomaly can be termed as collective outliers.
Machine learning algorithms use training data from the dataset to train the model. If an outlier is present in the dataset or training data, it will lead to spoiling of the training also it produces highly inaccurate predictions and less efficiency. Also in some cases like spamming or fraud detection, we need to analyze the error or outlier data to understand them and prevent them.
We have many methods for detecting the outliers, which are broadly classified into two types, which are
In the case of dealing with outliers some data, scientists remove the outliers completely and process the dataset. In another case, they just control the outlier numbers.
Now we have to check one method and how it deals with the outliers. Consider the method K clustering that makes the datapoints as some clusters with a mean value. Datapoints with close mean value are considered as it belongs to that cluster.
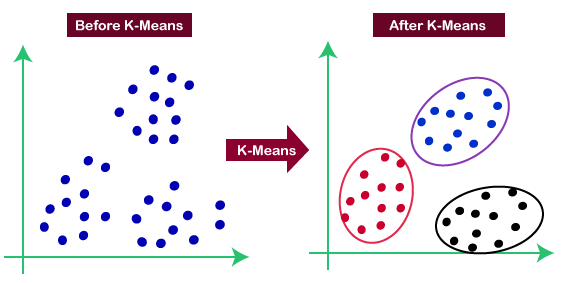
In this method for finding the outliers, we are using two things. First, we have to put a threshold value in such a way that if a data point is greater than the threshold value distance from the nearest cluster is considered as an outlier.
Second, we have to calculate a threshold distance between the test data and the cluster mean. Then if the distance between the test data and the closest cluster is more than the threshold value, we consider the test data as an outlier.
Data points with large residuals tend to skew the regression coefficients away from the general data trend. Cook's distance is a metric that assesses the impact of removing a data point, measuring the amount of influence a data point has.
The Yellowbrick library in Python has an implementation to compute Cook’s Distance. The documentation can be found here.
Outliers tend to alter the least-squares fit and have a higher impact than what we would expect, given the rest of the data.
Robust regression attempts to downweigh the influence of these outliers. This causes the residual to be significant, and data points are potential outliers to be easily identified.
The statsmodels library has a Robust Linear Model method. The documentation can be found here.
We have to check the impact of an outlier in the dataset that mainly considering two points.
Now we consider some tips to prevent the outliers

