In this tutorial, you will learn about how to import (read) data from various sources such as txt file, csv (comma-separated values) files. The data scientist usually stores data in Excel Spreadsheets. In the R programming language, there are several R packages such as XLConnect, xlsx, RExcel, gdata, RODBC, etc to access the data from Excel Spreadsheets. The R users or programmers save the spreadsheets (data) mostly in CSV format/files to take advantage of R‘s built-in functionalities to manipulate the data. So through this tutorial, you will learn the read (import) from .csv files in R language.
We need data to process our requirement, these data are read or imported into your program from spreadsheets or from any other sources for data analysis. The Microsoft Excel Spreadsheet is one of the most common ways to import data into R using a CSV file (Comma Separated Variable file). You can save your spreadsheet as a CSV file by making a copy of the same file and saving it in .csv file format. Let us see step by step how is spreadsheet converted to a .csv file type works with the R program.

There is some basic knowledge needed to know before reading a file into the R program. They are as listed below
getwd() function.setwd() function enables to set the current working directory.read.csv() function. 
getwd() function.Type getwd() in the R console it returns the current working directory as "C:/Users/John/Documents"
getwd()
[1] "C:/Users/John/Documents"
Suppose you need to change the current working directory because your file to read is saved under some other directories using setwd() function. The same can be done in RStudio by following the below steps
By choosing the file location you can change and set your current working directory.
One of the easiest ways to import datasets to the R program is using the import Dataset option in RStudio.
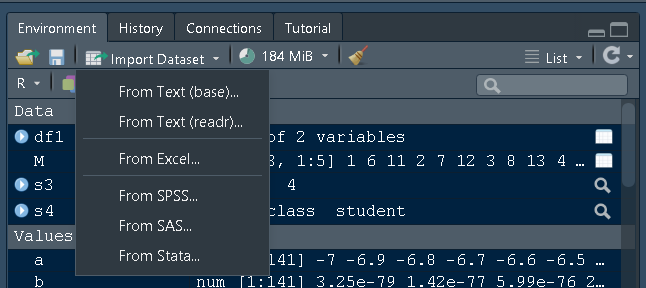
For importing text files use the first option from where you can browse and open the text file.
You can change the name of the dataset from here. Also, other options such as heading, row names, etc can be altered based on user requirements.
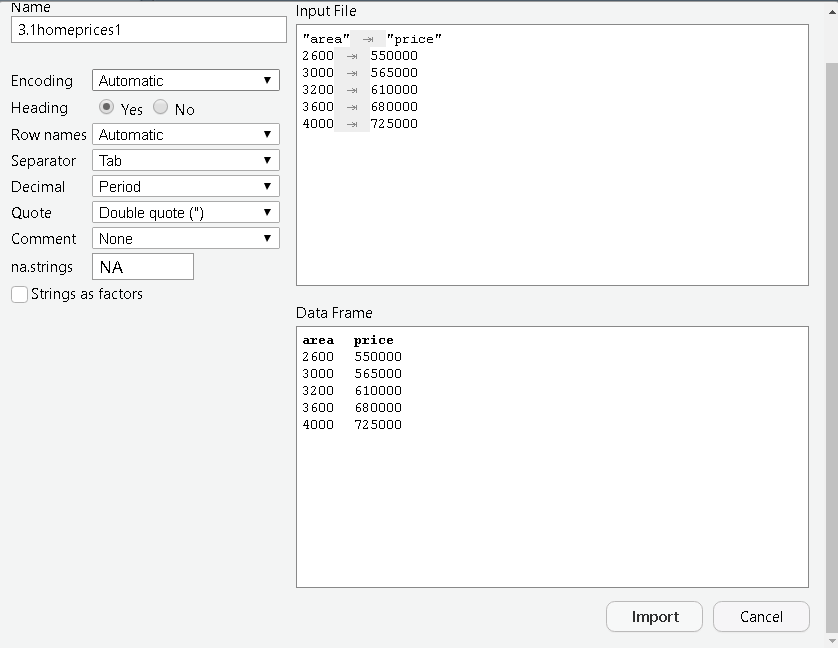
Click the Import button to load the dataset into the R program. You can view the same dataset loaded into Rscript. The object named 3-1homeprices gets created in a global environment.
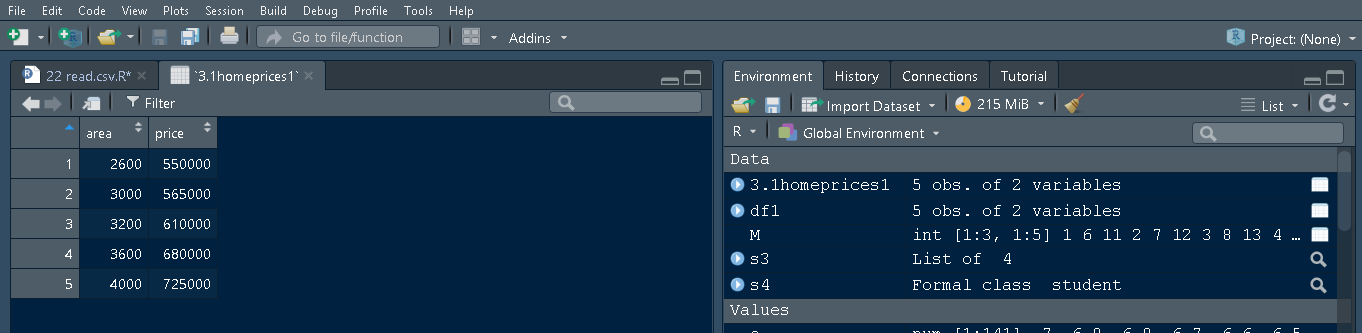
Note : The data by default store in the dataframe structure.
The R program allows loading the .csv file type into the workspace using a built-in method known as read.csv() or by loading or importing external packages and storing them as data frames (df). The method read.csv() is included in base R supports to load data to R script and execute the program.
In the below example the read.csv() function is used to load the data in the .csv file type with file name 3-1homeprices.You can specify the entire file path such as “C:\\Users\\Desktop\\R\\R Pgms\\3-1homeprices.csv" to load the data as long as the .csv file is saved in the same folder as your R script.
######importing Data ######
####using read.csv() ######
df1=read.csv(file ="C:\\Users\\Desktop\\R\\R Pgms\\3-1homeprices.csv" )
print(df1)
When the above piece of code is executed the data stored in the file gets displayed as
print(df1) area price 1 2600 550000 2 3000 565000 3 3200 610000 4 3600 680000 5 4000 725000
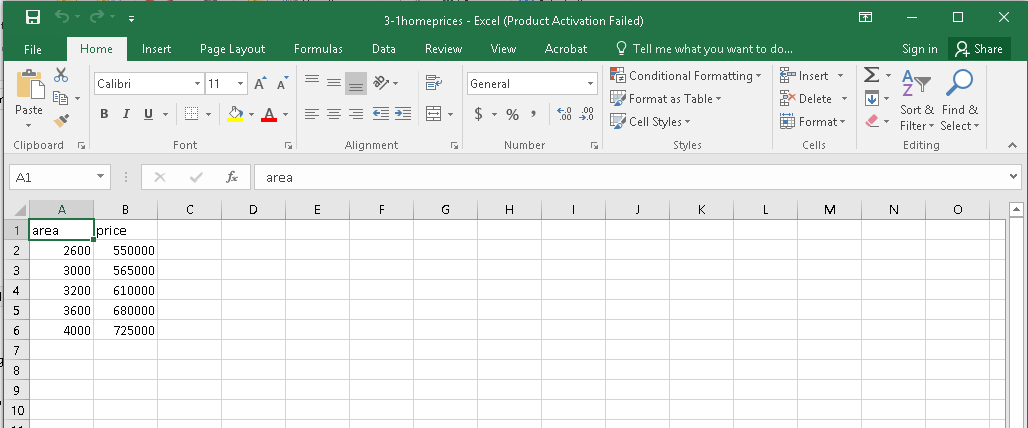
Compare the contents of data displayed in the R console with spreadsheet data, both are similar. So using the read.csv() function you can easily pull spreadsheet data into the R program. Look at the below screenshot.
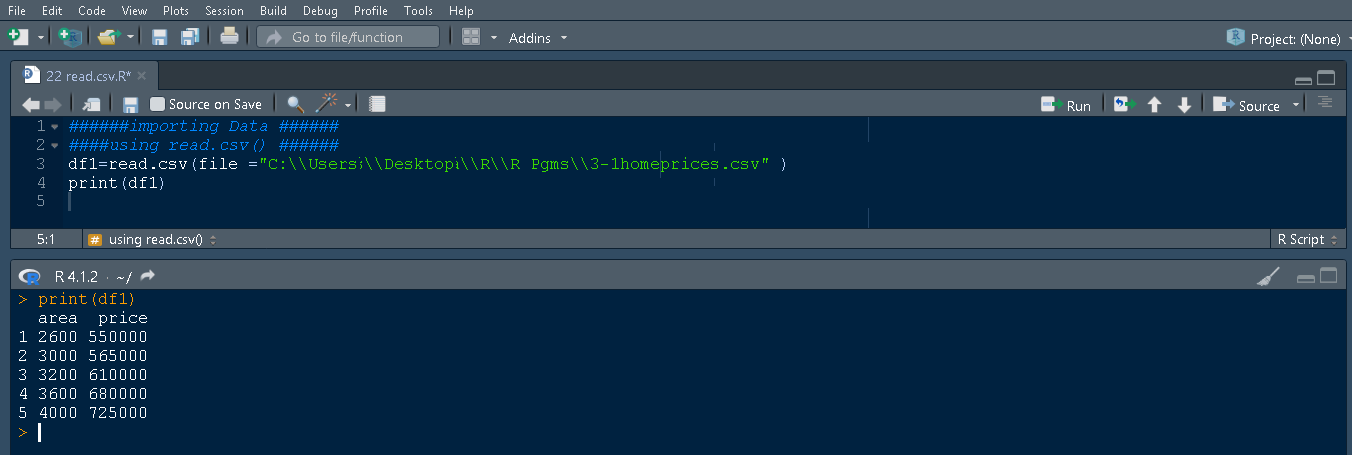
In the RStudio, you can view the data by clicking on df1 variable in Environment(right panel), which shows 5 observations of two variables as area and price in the left panel.
In the above example, we provided the full path in one step to read the data into a data frame named df1. This can be also achieved by mentioning the path in another step and just calling the path inside the function read.csv(). The syntax it follows is given below
read.csv(path, header = TRUE, sep = “,”)
Arguments :
The path “C:/Users/Desktop/R/R Pgms/3-1homeprices.csv” where the file resides is specified in a separate line by storing to a variable named path. When there is a requirement for loading a dataset simply call the name of the variable where the path is stored. In our example, the variable path holds the details of .csv location.
#path specifying
path = "C:/Users/Desktop/R/R Pgms/3-1homeprices.csv"
#loading data from .csv file
data = read.csv(path)
#Displays the data
print(data)
The code when executed fetches the data stored in .csv file as
area price 1 2600 550000 2 3000 565000 3 3200 610000 4 3600 680000 5 4000 725000
In case if the header is set to FALSE in the syntax ,the column header names area, prices will not be displayed. It will by default represent as V1,V2…etc depending upon the number of columns in the dataset
#path specifying
path = "C:/Users/Desktop/R/R Pgms/3-1homeprices.csv"
#loading data from .csv file with columns names are hidden
data = read.csv(path,header = FALSE)
#Displays the data
print(data)
The output will not specify the column names
V1 V2 1 area price 2 2600 550000 3 3000 565000 4 3200 610000 5 3600 680000
You are going to learn about two packages in R, readr and data.table.We will begin with setting the location or directory where the files or data resides using setwd() function.
Make sure to install the packages using the following commands
install.packages("readr")
#to load readr library
install.packages("data.table")
#to load data.table library
The screenshot gives the idea of working directory setup and installation of packages and importing the library using library() function with the name of the package to be imported inside the parentheses as arguments.
The readr library is created by the authors Madley, Jim, and Romain. The read.csv() function under readr package with some default arguments is used to load or import data.
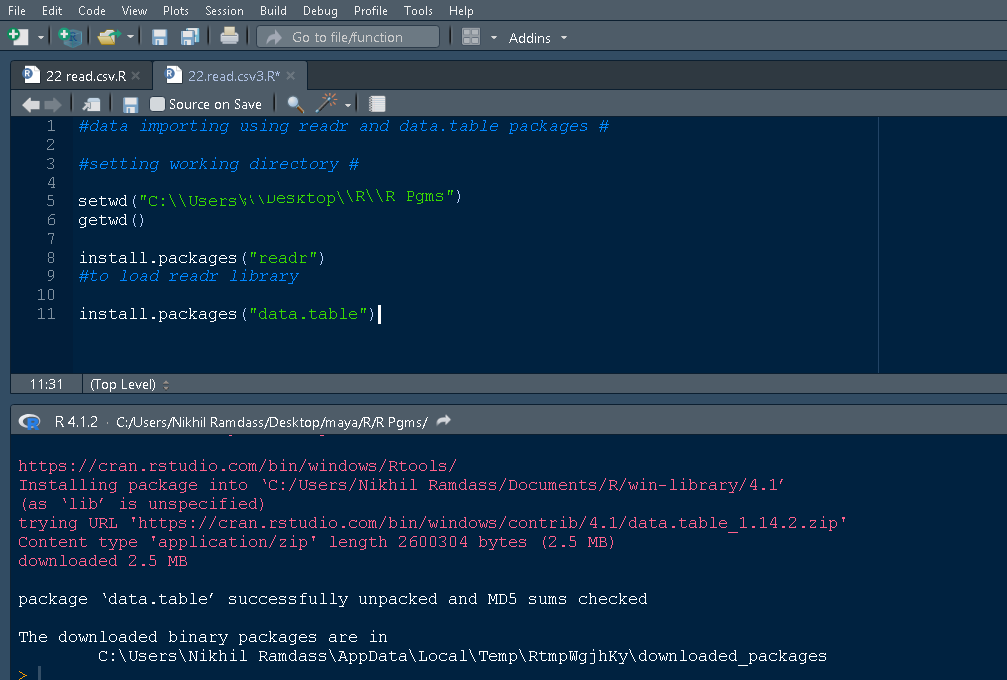
The whole data is read by giving the path and the object is stored as data.Two functions head() and str() further used whose output is as given in below screenshot.
data = read.csv(file ="C:\\Users\\Desktop\\R\\R Pgms\\3-1homeprices.csv")
head(data)
str(data)
The read.table() function is used to import text files into R program
df2= read.table(file ="C:\\Users\\Desktop\\R\\R Pgms\\3-1homeprices1.txt")
print(df2)
The output is
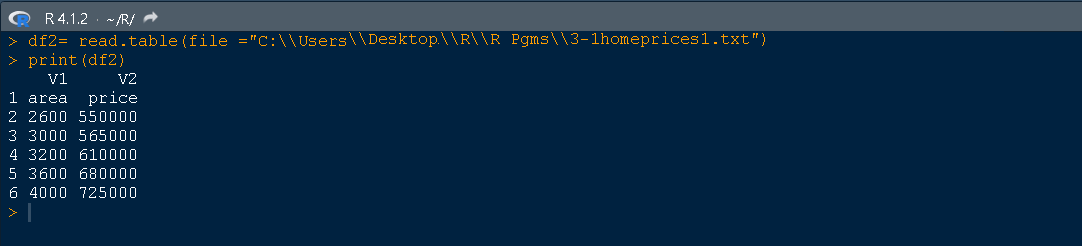
You can see there is more than one column in dataframe with V1,V2 above the columns.You can set header argument equals to TRUE to set the column names as actual headers insead of V1,V2 etc.
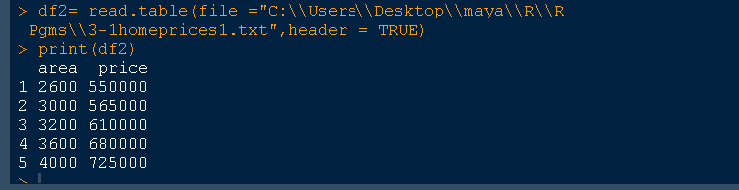
df2= read.table(file ="C:\\Users\\Desktop\\R\\R Pgms\\3-1homeprices1.txt",header = TRUE)
print(df2)
The output is given below where the V1,V2 is vanished with the headers area and price .