

In this tutorial, you will learn what a regular expression is and how it is useful in programming and how to implement pattern matching with the aid of some simple examples and figures. In addition, you will learn to import the module ‘re’ which covers some useful functions like a match, search,findall, etc.
Before discussing regular expression, let us think of specific functionality that we use in our daily life intentionally or unintentionally, that is, searching strings using “find”, finding and replacing strings using “find and replace”, in word processors and text editors, and validating the inputs like email and passwords, etc. How are these happening? The answer is in this tutorial.
What is a regular expression?
A regular expression is a sequence of characters that define some sort of search pattern. In a programming context, Regular expression plays a vital role since it defines a search pattern for a sequence of characters. Regular Expression is abbreviated as Regex.
For instance,
a*b = {b,ab, aab,aaab,aaaab,.......}
ab* = { a,ab, abb, abbb, abbbb,.....}
Here, a*b and ab* are regular expressions with languages {a,b} and * denotes zero or more.
Now let's start learning the implementation of regular expressions in Python, where to start, and how to start. In python, functions and methods for regular expressions are lodged in a module named re. So to perform any Regex functionality it is a must to import the re module. Below shows the prototype to import re module:
import re
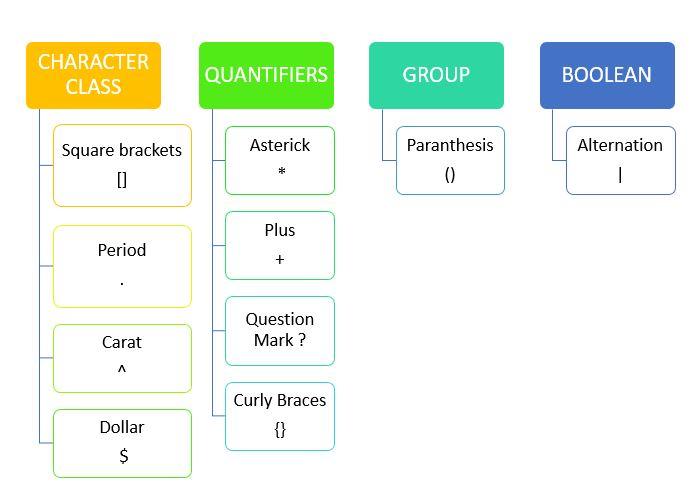
The power of regular expression is enhanced with the loom of special characters named meta characters. Metacharacters, in a regular expression, are characters that have special meaning to computer programs. Opening and closing square brackets ([]) , carat^ , dollar($),Period(.),Vertical bar(|), asterisk (*),plus(+), question mark(?), opening and closing curly braces({}), parentheses (), backslash( \) etc are some of the metacharacters used in Regex.
Based on the operations,metacharacters can be categorized as below:
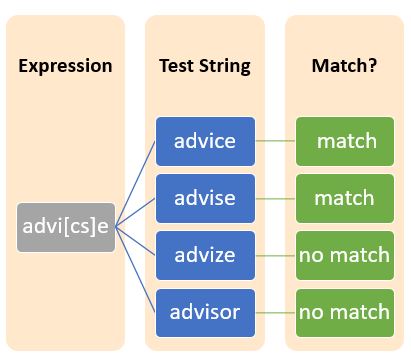
The square bracket is a metacharacter in regular expression which is used to define a character set. In other words, characters inside the square brackets form the character set and try to match any single character in the square bracket.
Example :
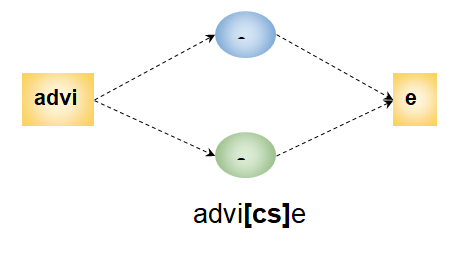
For better understanding, the regular expression can be visualized as
Using square brackets [] we can also represent a range of characters. “-” (hyphen) is used to represent a range of characters. For instance,
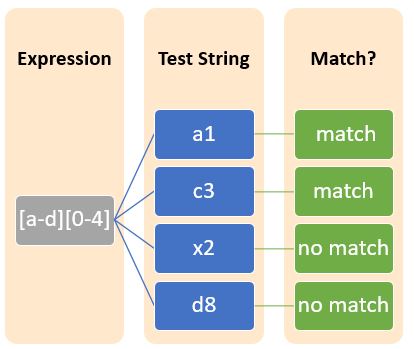
In this example,
[a-d] is a regular expression that is analogous to [abcd]
[0-4] is also a regular expression that is analogous to [01234]
It is also possible to invert the character set range. This can be done by placing a caret(^) symbol immediately after the opening of the square bracket. This can be viewed as :
The dot or period which specifies a wild card matches any single character other than a newline character. The number of dots represents the number of characters that can be included.
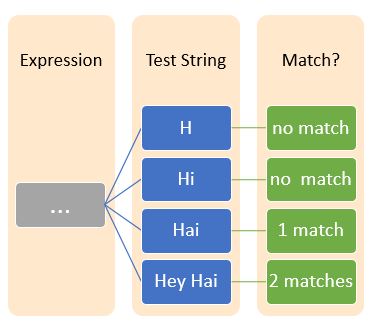
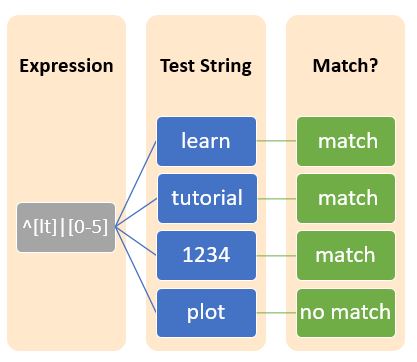
The metacharacter, ^(caret symbol) usually prefixed with a character indicates that the regular expression starts with that specific character.
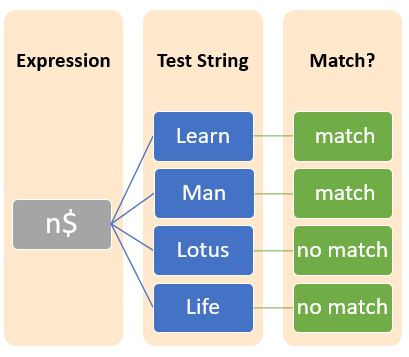
The metacharacter, $(dollar symbol) usually suffixes with a character denotes a regular expression that ends with that particular character.
Quantifiers in a regular expression represent the occurrences of a character, metacharacter, or a character set. *,+,? and {} belong to quantifiers.
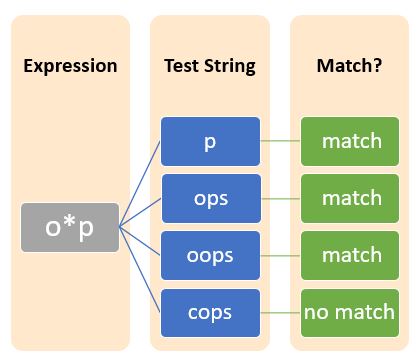
The Star or asterisk symbol (*) tells the zero or more occurrence of a pattern in the string.
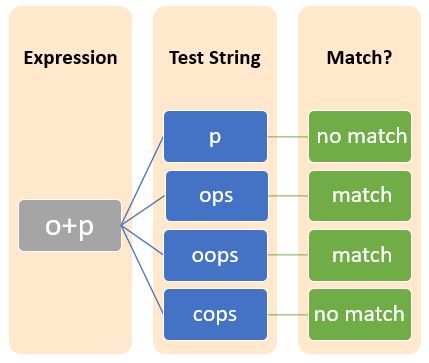
The plus symbol (+) indicates one or more occurrences of a pattern in the string.
The question mark(?) represents zero or one occurrence of a pattern in the string.
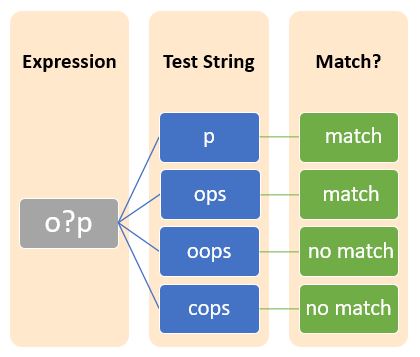
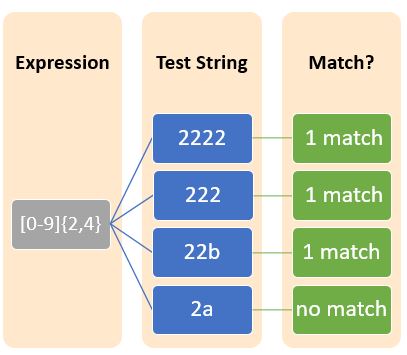
Curly braces also belong to the category of quantifiers which is used to represent the repetition of certain characters or metacharacters or character sets. Braces can take the following forms:
| {n} | The preceding character is repeated exactly n times. |
| {n,} | The preceding character is repeated at least n times |
| { ,m} | The preceding character is repeated utmost m times |
| {n,m} | The preceding character repeated between n and m times, both inclusive. |
The alternation is commonly used for accomplishing the Logical OR operation by representing this or that. This can be accomplished by pipe symbol (|) and it matches a single regular expression with any of possible regular expressions.
A regular expression of the form <regex-1>|<regex-2>|....|<regex-n> matches with utmost one of the <regex-i>.
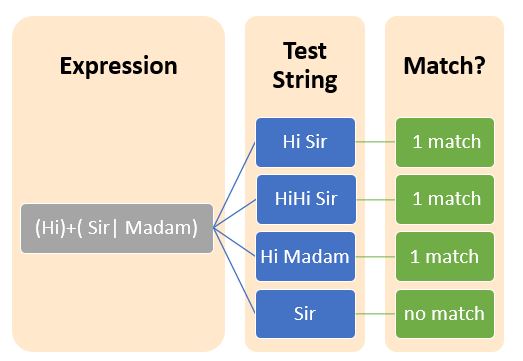
Grouping constructs splits the regular expression into small groups of subexpressions. Grouping can be accomplished with parenthesis() symbols.
| Regex | Interpretation | Example/Matches |
|---|---|---|
| (Hi)+ | + Applies to entire character set | Hi HiHi HiHiHi |
| Hi+ | + Applies to the character “i” only | Hi Hii Hiiii |
| Regex | Interpretation | Example/Matches |
|---|---|---|
| This is a car|bus | | applies to ‘This is a car ‘ and ‘bus’ | This is a car bus |
| This is a (car|bus) | | applies to ‘This is a car’ and ‘This is a bus’ | This is a car This is a bus |
With the help of a group construct, we can also extract some pieces of strings that match the subexpression or subpattern. Two methods associated with group constructs to capture strings are group () and groups() which you will learn later in this tutorial.
The backslash (\) in the regular expression is used for escaping special characters including the metacharacters. By placing a backslash before metacharacters will remove the special meaning of metacharacter and will specify it as a literal character itself. For instance, Metacharacter (?) Question Mark can be considered as a literal character by putting a (\) character prior to it.
Also, the backslash is useful in cases where you are uncertain about the meaning of some characters and can be verified by placing the backslash before the character.
In a regular expression, a special sequence is a sequence with a character prefixed with a backslash. Listed below are special sequences with their meanings and examples for easy understanding

Now you are well acquainted with metacharacters and special characters used in regular expressions This section will teach you to implement them with some of the common and often used regular expression functions. Listed below are popular functions associated with re module.
A detailed explanation of each function is provided below with simple and easy-to-understand examples.
Examine the below-given code which uses the match() function to validate email format.
import re
string = '[email protected]'
pattern = '^[a-zA-Z0-9+_.-]+@[a-zA-Z0-9.-]+$'
result = re.match(pattern, string)
if result:
print("Valid email format")
else:
print("Invalid email format")
Output:
Valid email format
In this example, we have used a match function to check whether the pattern matches with the provided string. Here we validate the email format with a regular expression and if the test string does not follow the pattern an invalid email format will be printed as output.
Another method associated with the re module to manipulate regular expression is the search() method which takes two arguments - a pattern and a string. As its name suggests, this method searches for the initial location where the pattern matches with the string. If it finds a perfect match, then re. search() will return a match object else a None will be produced as the outcome. Following is the example:
import re
string = 'Python is a universal programming language developed by a Dutch Programmer called Guido Van Rossum in 1989 and released in 1991'
pattern ='\d'
result = re.search(pattern, string)
if result:
print("search successful")
else:
print("search unsuccessful")
Output:
search successful
Here, the result contains a match object.
This method scans a string in the left to the right direction and returns a list of all the matches in the order found.
import re
string = 'Python is a universal programming language developed by a Dutch Programmer called Guido Van Rossum in 1989 and released in 1991'
pattern ='(\d+)'
result = re.findall(pattern, string)
if result:
print(result)
else:
print("search unsuccessful")
Output:
['1989', '1991']
In case there is no match found, then an empty list will be the outcome.
This method is slightly different from the above methods we have learned. In this method, the string gets split based on the pattern match and the outcome will be a list of strings where the split has taken place. Observe the below example:
string = 'Python is a universal programming language developed by a Dutch Programmer called Guido Van Rossum in 1989 and released in 1991.'
pattern = '\d+'
result = re.split(pattern, string)
print(result)
Output:
['Python is a universal programming language developed by a Dutch Programmer called Guido Van Rossum in ', ' and released in ', '.']
In the above code snippet, the string splits when the digits are encountered. When there are no matches found, the spit() method returns a list with the original string. Another peculiarity of the split method is the ability to limit the number of splits by specifying a value to the argument, max split.
import re
string = 'Python is a universal programming language developed by a Dutch Programmer called Guido Van Rossum in 1989 and released in 1991.'
pattern = '\d+'
result = re.split(pattern, string,1)
print(result)
Output:
['Python is a universal programming language developed by a Dutch Programmer called Guido Van Rossum in ', ' and released in 1991.']
Note:By default , value of maxsplit is zero (all possible splits)
This method replaces the matches with strings of the desired choice
import re
string = 'abc 123 def 456 ghi 789'
pattern = '[a-z]'
replace = '0'
result = re.sub(pattern,replace,string)
print(result)
Output:
000 123 000 456 000 789
Like split(), you can limit the number of replacements by setting the value to an optional argument, count. By default, the value of count is zero which means all possible replacements will take place.
import re
string = 'abc 123 def 456 ghi 789'
pattern = '[a-z]'
replace = '0'
result = re.sub(pattern,replace,string,4)
print(result)
Output:
000 123 0ef 456 ghi 789
In the above methods, you have seen an optional parameter called flags which are modifiers used to control various aspects of matching. By default, flags are assigned to zero.
Match objects in the regular expression are objects which contain the information about the search and the result. Match objects always contain truth values either True or False. If there is no match then instead of a match object, None will be returned. Observe the output of the following code:
import re
string = 'I am 18 years old.'
pattern = '\d+'
result = re.search(pattern, string)
print(result)
Output:
span=(5, 7), match='18'
The match object has the following properties and methods to get the information of search and result:
span(): returns a tuple with starting and ending indexes of the match.
group(): returns the portion of the string that matches the pattern
String: returns the passed string
import re
string = 'I am 18 years old.'
pattern = '\d+'
result = re.search(pattern, string)
print(result.span())
print(result.group())
print(result.string)
Output:
(5, 7) 18 I am 18 years old.
To learn more about the properties and methods associated with match objects please visit the documentation page of python.

