

In this section, we will discuss how to manipulate strings in the R programming language with different types of in-built functions provided by R packages.
A brief summary of function names and their corresponding actions or performance is described in the below table.
| String Manipulations Functions | Description |
|---|---|
| paste() | To concatenate the strings. |
| format() | To format the numerical values. |
| nchar() | To count the characters in the string. |
| substr() | To extract the specific characters from the string |
| grep() | To extract a specific pattern from a string. |
| strsplit() | To split the elements in a character string. |
| tolower() | Translates lower to upper case strings |
| toupper() | Translates upper to lower case strings |
Let us go into detail with each function.
The paste () function in R is used to combine two strings or more than two strings together to form a new string. In other words, the paste() function concatenates vectors after converting them into characters.
The paste function converts the arguments present in it to character strings and they are concatenated. If the arguments are vectors, they are concatenated term-by-term to give a character vector result. Vector arguments are recycled as needed, with zero-length arguments being recycled to " " only if recycle0 is not true or collapse is not NULL.
paste (..., sep = " ", collapse = NULL, recycle0 = FALSE)
paste0(..., collapse = NULL, recycle0 = FALSE)
Where,
If a value is specified for collapse, the values in the result are then concatenated into a single string, with the elements being separated by the value of collapse.
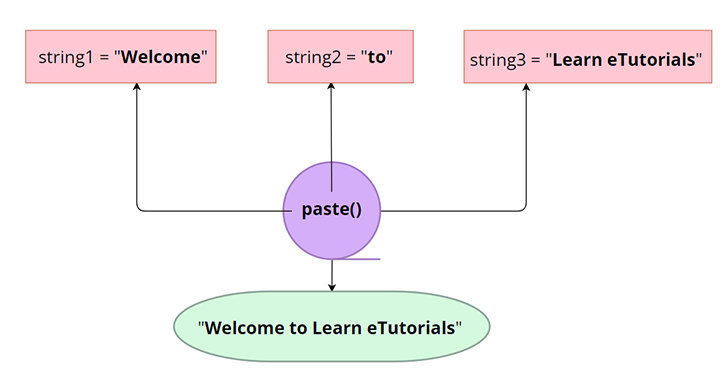
#use paste() function
string1 = "Welcome"
string2 = "to"
string3 = "Learn etutorials" c string2, string3)
print(concatStr)
Output:
[1] "Welcome to Learn etutorials"
paste("Welcome", "to"," Learn etutorials ", sep = "----") #paste with separator
The sep=”---“ is a character string that separates arguments welcome, to, Learn etutorials given inside a paste() function.
Output:
[1] "Welcome----to---- Learn etutorials "
When the separator is changed to sep=”___” the input and output becomes
> paste("Welcome", "to"," Learn etutorials ", sep = "___") #paste with separator
[1] "Welcome___to___ Learn etutorials "
x <- c("example","of","paste","with","collapse")
print(x)
paste(x)
The vector object x contains several different character strings. When the paste function is applied over this vector object x, it returns the corresponding result the same as a vector output. Let us see the output to differentiate vector output(print x) and when paste() function is applied to vector x (paste(x))..
> print(x)
[1] "example" "of" "paste" "with" "collapse"
> paste(x)
[1] "example" "of" "paste" "with" "collapse"
You can observe that both results are the same. The character strings of vector object x are not merged with the paste function. So in order to merge elements of a vector object you need to specify the collapse argument.
paste(x,collapse = " ")
In the collapse argument, you need to specify another character string as a separator. Here collapse = “ “ implies the vector object x elements is going to merge with a blank value. When the code is run the output is
paste(x,collapse = " ")
[1] "example of paste with collapse"
Another character string is returned by merging all elements in the vector.
| paste() | paste0() | |
|---|---|---|
| INPUT | paste("Welcome", "to"," Learn etutorials ", sep = "") | paste0("Welcome", "to"," Learn etutorials ") |
| OUTPUT | [1] "Welcome to Learn etutorials " | [1] "Welcome to Learn etutorials " |
| INFERENCE | Need to specify a separator ie sep. | No need to specify a separator. By default uses an empty character string as a separator. |
Inference: paste0() function is an alternative provided in the R programming language instead of the paste() function which is a more efficient and convenient function for merging strings. From the above table, it is clear that both paste() and paste0() provide similar output.
The nchar() function in the R programming language counts the number of characters including spaces in a string. This function consists of a character vector as its arguments and returns a vector whose elements comprising of different sizes of the elements of a string. The nchar function in R is the fastest and most efficient way to find out if elements of a character vector are non-empty strings or not.
nchar(x, type = "chars", allowNA = FALSE, keepNA = NA)
nzchar(x, keepNA = FALSE)
Where Arguments
Consider an example with a single character object or a variable string str0.To check how many number characters are contained in string str0 we apply nchar() function over str0. The function returns a corresponding value in the RStudio console. In our example applying nchar() in str0 returns a value of 27. Each character is counted including the space that separates two words within a given single string.
# use nchar() function
#Returns the count of number of characters including space present in it
str0 = "welcome to Learn eTutorials" #create a character object /string str0
print(nchar(str0)) #Apply nchar() in R
The output returns the character count value.
Output:
[1] 27
Now let us consider an example using vector datatype. A vector str1 is created using c() function with 4 elements welcome", "to", "Learn", "eTutorials" respectively. Applying nchar() over str1 returns the count of characters in each different word or string inside the given vector str1.For example the string “welcome” a word/element inside vector return a value 7 after application of nchar function and so on for remaining elements too.
str1=c("welcome","to","Learn","eTutorials")
print(str1)
nchar(str1)
Output:
> print(str1) [1] "welcome" "to" "Learn" "eTutorials" > nchar(str1) [1] 7 2 5 10
From the output, you can see how many characters correspond to each character string contained in the given vector.
In order to deal with NA values present within a given input, an optional argument keepNA provided in nchar() function.
vector0<- c(NA,"R", 'TUTORIAL', NULL)
nchar(vector0, keepNA = FALSE)
A vector named vector0 is created with a few elements inside it. Let us see first how the vector output gets displayed.
print(vector0)
[1] NA "R" "TUTORIAL"
The above strings are displayed in the R console after executing the shortcode. Now let us find what change does happens to the same code after applying nchar () and together with the addition of another optional argument 'keepNA'.
> nchar(vector0)
[1] NA 1 8
The NA value is excluded from counting the characters of each string of the given vector, i.e. vector0. The function counts the rest of the string's characters and returns the value as shown like “R” with 1 character, “TUTORIAL” with 8 characters, and so on.
When keepNA is set to TRUE, keepNA=TRUE, produces the same result as above.
nchar(vector0, keepNA = TRUE)
[1] NA 1 8
The NA is not counted, by changing the value from TRUE to FALSE, allows the nchar() function to count the NA if exists in the given input and returns its corresponding value.
> nchar(vector0, keepNA = FALSE)
[1] 2 1 8
The only difference between nchar() and nzchar() function is that nchar returns numeric values whereas nzchar() returns a logical value. Consider the nzchar() applied to the same vector0 created used in our examples, with an optional argument keepNA set to FALSE.
nzchar(vector0, keepNA = FALSE)
The output produced is
[1] TRUE TRUE TRUE
In case vectors contain any empty string represented as “ ” with a non-empty string, they will return a FALSE value.
Look at the table below
| nchar() | nzchar() | Difference |
|---|---|---|
| vector0<- c(NA,"R", 'TUTORIAL', NULL) nchar(vector0, keepNA = FALSE) | vector0<- c(NA,"R", 'TUTORIAL', NULL) nzchar(vector0, keepNA = FALSE) | nchar() returns a numeric vector with same length as vector(vector0) as output. |
| [1] 2 1 8 | [1] TRUE TRUE TRUE | |
| nchar(vector0, keepNA = TRUE) | nzchar(vector0, keepNA = TRUE) | nzchar() returns a logical vector with same length as vector(vector0) as output. |
| [1] NA 1 8 | [1] NA TRUE TRUE |
The format() function in the R programming language deals with treating all vector elements as character strings by encoding the vector objects into a common format.
format(x, trim = FALSE, digits = NULL, nsmall = 0L,
justify = c("left", "right", "centre", "none"),
width = NULL, na.encode = TRUE, scientific = NA,
big.mark = "", big.interval = 3L,
small.mark = "", small.interval = 5L,
decimal.mark = getOption("OutDec"),
zero.print = NULL, drop0trailing = FALSE, ...)
Where Arguments
big.mark, big.interval, small.mark, small.interval, decimal.mark, zero.print, drop0trailing used for prettying (longish) numerical and complex sequences. Passed to prettyNum:
#use format() in R
# Place string to the left side
StrFormat1 <- format("Learn eTutorials", width = 25, justify = "l")
# Place string to the center
StrFormat2 <- format("Learn eTutorials", width = 25, justify = "c")
# Place string to the right
StrFormat3 <- format("Learn eTutorials", width = 25, justify = "r")
# Display the different string placement
print(StrFormat1)
print(StrFormat2)
print(StrFormat3)
Output:
[1] "Learn eTutorials " [1] " Learn eTutorials " [1] " Learn eTutorials"
# R program to illustrate format function
# Calling the format() function over different arguments
# Rounding off the specified digits
numformat1 = format(1.45677, width = 10,digits=2)
numformat2 = format(1.45677,width = 10, digits=4)
numformat3 = format(1.45677,width = 10, justify = "r" ,digits=4)
print(numformat1)
print(numformat2)
print(numformat3)
# Getting the specified minimum number of digits
# to the right of the decimal point.
numformat3 = format(1.45677, nsmall=3)
numformat4 = format(1.45677, nsmall=7)
print(numformat3)
print(numformat4)
Output:
[1] " 1.5" [1] " 1.457" [1] " 1.457" [1] "1.45677" [1] "1.4567700"
The most useful arguments in format () to format a string is
width To produce minimum width.trim No padding with spaces when set to TRUEjustify Takes the values "left", "right", "centre", and "none" to control the padding in strings.The below arguments are useful for controlling the printing of numbers,
digits The number of digits to the right of the decimal place.scientific use TRUE for scientific notation, FALSE for standard notationIn R, the function substr() extracts and returns part of a string from the whole given input string. For the process of extracting a part from a string, a start and stop integer needs to be considered. When the substr() is applied to a string, the extraction begins with the starting integer till it reaches the stop or ending integer. Once it reaches the referred stop integer the function returns the extracted substring.
substr(x, start, stop)
Where Arguments
str = "hello Learn eTutorials learners"
substr(str,6,21)
The part of the string after extraction of string str from starting integer 6 and terminating integer 21 is
[1] " Learn eTutorial"
Similarly, a vector does perform in the same manner. Consider a vector str0 with a list of elements or strings like "hello"," Learn"," eTutorials"," learners".
str0=c("hello"," Learn"," eTutorials"," learners")
substr(str,6,21)
The grep function or grep() in R facilitates the task of identifying or searching a specific pattern within a string. The grep function returns the number of instances of a searching pattern if they do find a match similar to the pattern in the string.
The grep() is a pattern matching and replacement function used in R. The grep, grepl, regexpr, gregexpr, regexec and gregexec search for matches to argument pattern within each element of a character vector:
sub and gsub perform replacement of the first and all matches respectively.
grep(pattern, x, ignore.case = FALSE, perl = FALSE, value = FALSE,
fixed = FALSE, useBytes = FALSE, invert = FALSE)
grepl(pattern, x, ignore.case = FALSE, perl = FALSE,
fixed = FALSE, useBytes = FALSE)
Where Arguments
| ignore.case=TRUE | Ignores case-sensitivity while pattern matching. Eg pattern =” Learn” Match with all other possible patterns irrespective of its case representation “learn”, “LEARN” etc. |
| ignore.case=FALSE | Includes the case sensitivity while finding a match. Eg pattern =” Learn” Match only with “Learn” not with “learn”, “LEARN” etc. By default use FALSE against case sensitive option. |
| fixed=TRUE | the pattern is a string to be matched as it is., which indicates pattern matching needs to be exact |
| fixed=FALSE | No restriction upon exact pattern match (default) |
| useBytes=TRUE | byte-by-byte pattern matching |
| useBytes=FALSE | character-by-character matching |
| invert = TRUE | If TRUE returns indices or values for elements that do not match. |
| Invert = FALSE | If FALSE returns indices or values for elements that do match. |
Consider the code below a vector named str0 with the following elements "hello"," Learn"," eTutorials"," Learners"
str0=c("hello"," Learn"," eTutorials"," Learners")
Suppose you need to check a pattern “Learn” in the vector str0. You can use the grep() here.
grep("Learn",str0)
The output after applying to grep() in str0 is
[1] 2 4
The grep() searches pattern & returns a number of instances. For example, the search pattern “Learn” return the number of instances it occurs at 2, 4.
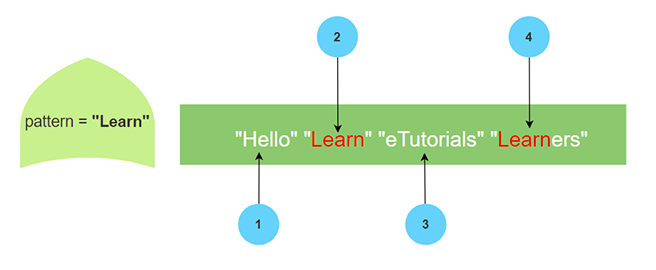
Consider the input character vector str0 with a list of character elements or strings.
str0=c("hello"," Learn"," eTutorials"," learners","LEARN","learN")
The table below shows use cases of ignore.case with grep()
| grep("Learn",str0) | [1] 2 | By default ignore.case is FALSE ignores case sensitive strings while pattern matching. |
| grep("Learn",str0,ignore.case = FALSE) | [1] 2 | if FALSE, the pattern matching is case sensitive |
| grep("Learn",str0,ignore.case = TRUE) | [1] 2 4 5 6 | if TRUE, case is ignored during matching. |
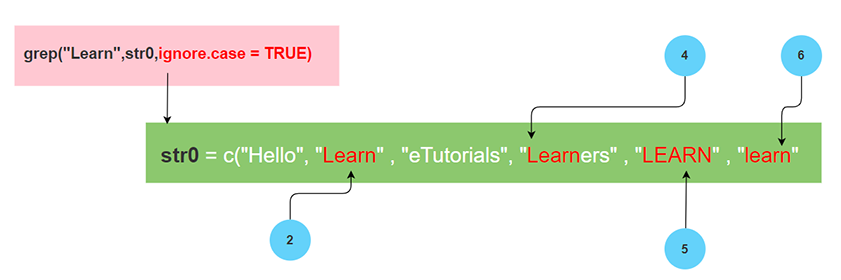
str0=c("hello"," Learn"," eTutorials"," learners","LEARN","learN")
> grep("Learn",str0,ignore.case = TRUE,value = TRUE,fixed = TRUE,useBytes = TRUE,invert =TRUE)
[1] "hello" " eTutorials" " learners" "LEARN" "learN"
Description against each argument in grep() for the above example
| pattern | "Learn" |
| x | str0 |
| ignore.case = TRUE | Ignores case sensitivity and returns all matching patterns |
| value = TRUE | Returns matching elements itself not indices of matched elements, |
| fixed = TRUE | Exact match is returned |
| useBytes = TRUE | Byte-by-byte matching |
| invert =TRUE | Returns values that do not match in output. |
The output after applying to grep() in the str0 vector is
[1] "hello" " eTutorials" " learners" "LEARN" "learN"
where these are patterns that do not match with the given pattern.
Consider what happens when all arguments in the above code are set to FALSE.
grep("Learn",str0,ignore.case = FALSE,value = FALSE,fixed = FALSE,useBytes = FALSE,invert = FALSE)
[1] 2
The value if FALSE, a vector containing the (integer) indices of the matches determined by grep() is returned. The pattern “Learn” matches exactly with indices 2 of the str0 vector.
Another simple example is to better understand the argument's value and invert. Returns non-matching elements as themselves ie as character vectors. The indices are not returned in these cases.
Try to understand each argument and observe the changes from below given code.
> str0=c("hello"," Learn"," eTutorials"," learners","LEARN","learN") # vector str0
> str0
[1] "hello" " Learn" " eTutorials" " learners" "LEARN"
[6] "learN"
> grep("Learn",str0) # grep() to extract pattern
[1] 2
> grep("Learn",str0,invert = TRUE) #Non matching elements are extracted using invert
[1] 1 3 4 5 6
> grep("Learn",str0,value = TRUE,invert = TRUE) #value return character vector itself not indices.
[1] "hello" " eTutorials" " learners" "LEARN" "learN"
>
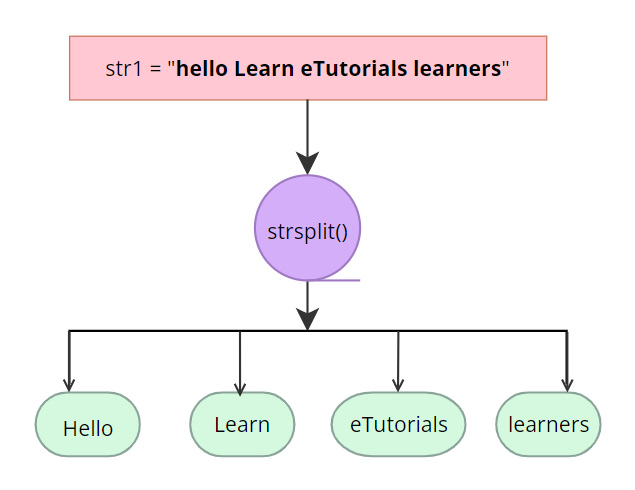
The strsplit() in R is a function to split the elements of a character vector. The strsplit() splits the given character vector(string) x into substrings based on the split argument provided within the syntax. The split argument indicates the character vector upon which the string is split into substrings.
strsplit(x, split, fixed = FALSE, perl = FALSE, useBytes = FALSE)
Where the argument
Consider the character variable or string str1 "hello Learn eTutorials learners" applying strsplit() with the split argument as “ ” returns a list of characters or elements of the string by splitting the string str1 at the blank spaces as "hello" "Learn" "eTutorials" "learners".
str1 = "hello Learn eTutorials learners"
> print(str1)
[1] "hello Learn eTutorials learners"
> strsplit(str1, " " )
[[1]]
[1] "hello" "Learn" "eTutorials" "learners"
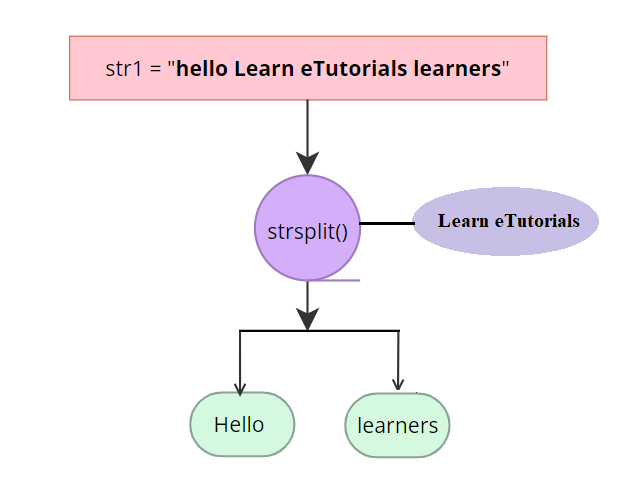
Consider another example to find the purpose of strsplit()
str1 = "hello Learn eTutorials learners"
print(str1)
strsplit(str1, "Learn eTutorials" )
The string is split at the position mentioned by argument split, here split is “Learn eTutorials”.Let us find its output
[1] "hello" "learners"
The tolower() in R turns the character string into lowercase. The just opposite of tolower() is done by function toupper. The toupper() turns the character string to uppercase.
| Description | tolower() & toupper() translates characters in character vectors from upper to lower case and vice versa. |
| SYNTAX | tolower(x) toupper(x) where x is input character string. |
| Example tolower(x) | x= "HELLO" > print(x) [1] "HELLO" > tolower(x) [1] "hello" |
| toupper(x) | > x= "hello" > print(x) [1] "hello" > toupper(x) [1] "HELLO" |

