

We already discussed supervised learning that is divided into regression and classification. We learned about regression and the methods of regression in previous tutorials. Now we are going to discuss classification algorithms.
Classification algorithms work on the principle of supervised learning as it needs a training dataset for training the model. In the classification algorithm, we are classifying the data into different categories based on a training dataset.
For example, we want to classify the emails as spam or not spam or in simple words, we have to classify according to the sex as male and female, Alternatively Yes or No, etc.
When compared to regression the output of the classification algorithm is different which will be a category that uses the supervised method of train dataset to predict an output. The classification algorithm can be represented using the formula,
y=f(x), where y = categorical output
Using a simple picture we can learn more about the classification whose main objective is to classify the data into different categories. In the below picture there are two classes that have different properties and features. So our objective is to separate the data that have similar properties into one and other similar properties into another class.
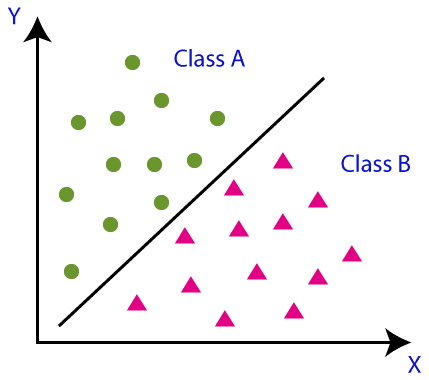
Classifications can be divided into two types and before that, we have to understand the term classifier. A classifier is nothing but the algorithm that is used in the dataset to classify the data.
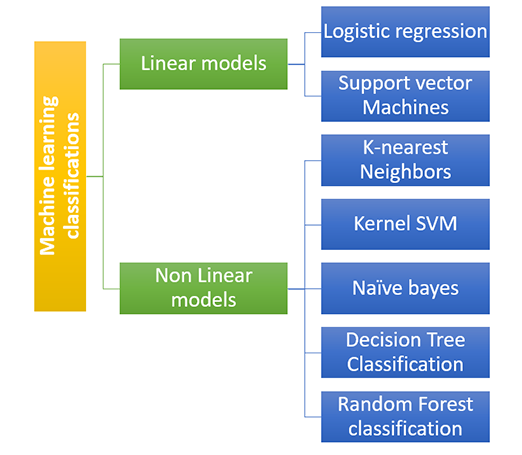
Classification algorithms are broadly divided into two types
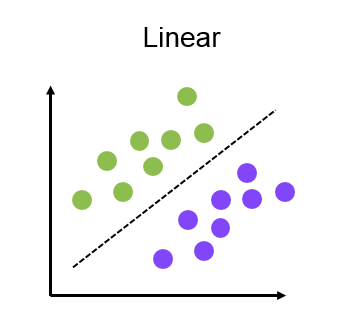
The linear model can be divided into
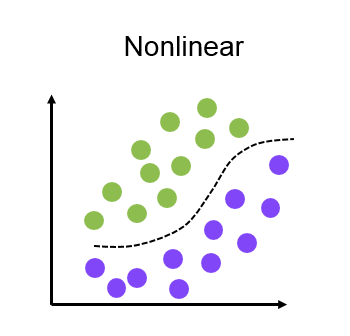
Nonlinear models can be are of different types which are
As the name suggests in lazy learners the train dataset will be stored and that will wait until the real data enter and do the classification and training the model. Here classification is based on the related data stored in the training dataset. In lazy learners it will take more time for predictions but less time for training. Examples are the K-NN algorithm and case-based reasoning.
Eager learners make the model as soon as they got the training dataset. It does not wait for the test dataset as we saw in the lazy learners. It will make the model before the test data arrives. For example Decision trees, Naïve Bayes, ANN, etc.
In supervised learning, both the classification and regression models need to get evaluated once it is completed. In the classification model, we have three types of evaluation which are
It is the most common method used in the supervised learning method for measuring the accuracy of a classifier. We will divide the dataset in to train the dataset and the test dataset.
After that, we provide the model with the training dataset which has the dataset and their corresponding category. Then the model will get learned with the training dataset. Then we provide the test data set to the model which has the dataset but not a corresponding category. The model has to predict the category of the test dataset accurately.
Confusion matrix or the error matrix will get the output in the form of a matrix that will describe our model performance. The matrix rows and columns contain the result in short format, which contains how many correct and incorrect predictions. Check the matrix below to get an idea.

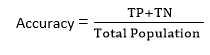
Log loss is a method that is perfect for the binary classification model which means the output will be between the number zero and one. In this method, we assume that lower the log loss value means high accuracy because log loos value increases if the difference in the predicted value and real value is very large. In binary classification, the cross-entropy is calculated as
?(ylog(p)+(1?y)log(1?p))
Where the ‘y’ is actual output and ‘p’ is the predicted output

