

What will you think when you see the term supervised learning; the same logic is applied here too. In supervised learning, there will be a supervisor while the machine learns.
Supervised learning means we have to provide a sample data called training data for train the machine. This train data contains the correct answer. After training the machine, we provide the new data that we need to test. The machine will check the new data with the training data we provided earlier and predict the output.
For better understanding, consider an example that we have a basket of some vegetables, which we need to classify.
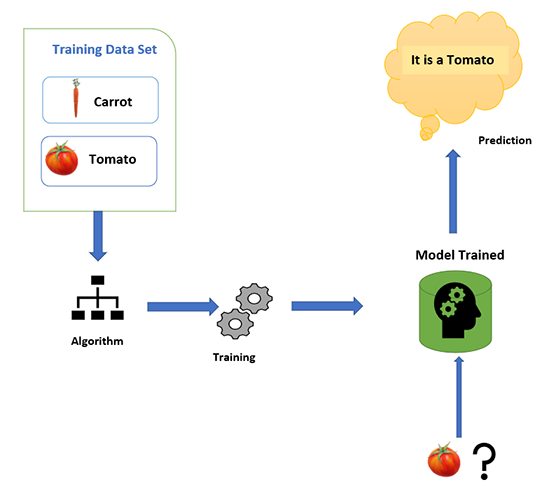
First, we are taking the sample vegetables from the basket.
Suppose we take a carrot and we feed the characteristics of carrot to machine-like long, tapering towards front and orange in color.
Next, we take a tomato then we feed it to the machine-like it's red in color and pulpy and round in shape.
Then we are providing the vegetables to the machine and the machine correctly identifies the carrot and tomato with the help of the details we feed to the machine.
The details we first feed to the machine are called Train data and the process is called Training the machine. Then we give input data is called Test data and the machine gives prediction on basis of Supervised learning.
In supervised learning, we are providing the input and the output and machine aiming to find some mapping relation to map the input variable with the output.
In our world supervised learning is used in various fields like fraud detection, email filter, image classification, etc.
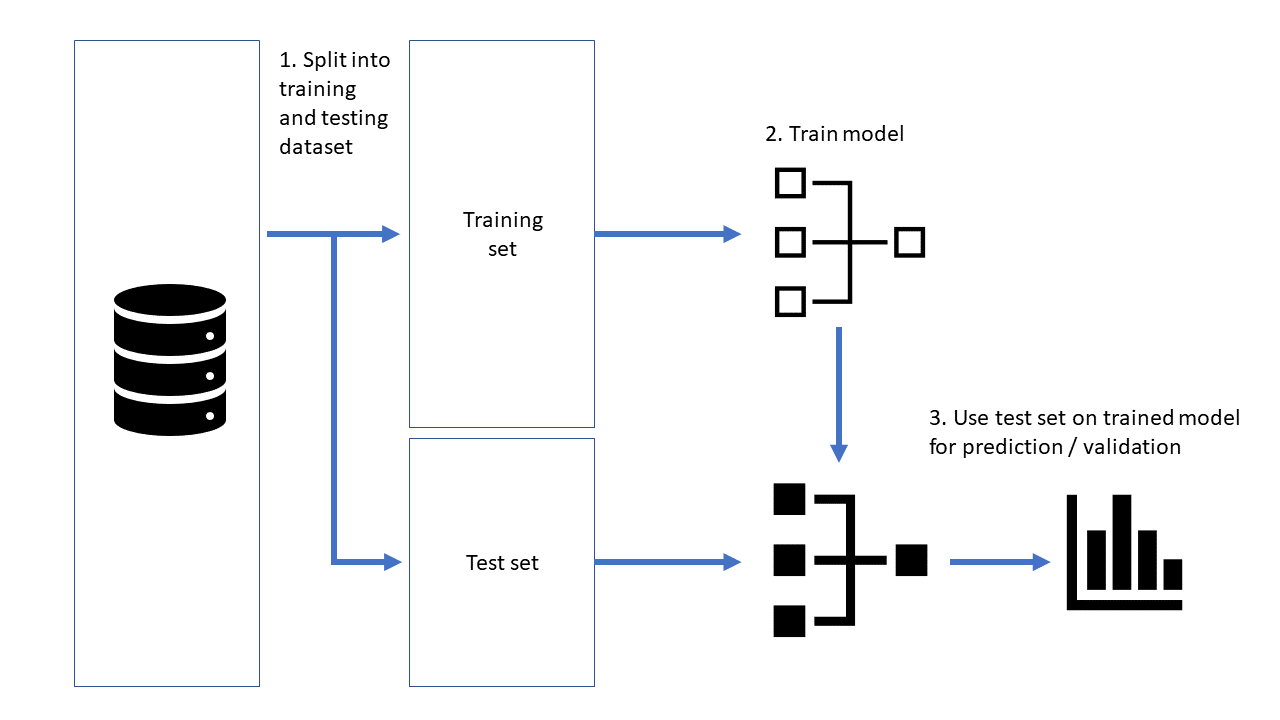
As we know supervised learning involves the training of models, using some sample data called training data. In this training, models will learn about the data in the dataset and they can analyze and predict the output of the new data we will provide.
Suppose we have some objects having different shapes and colors.
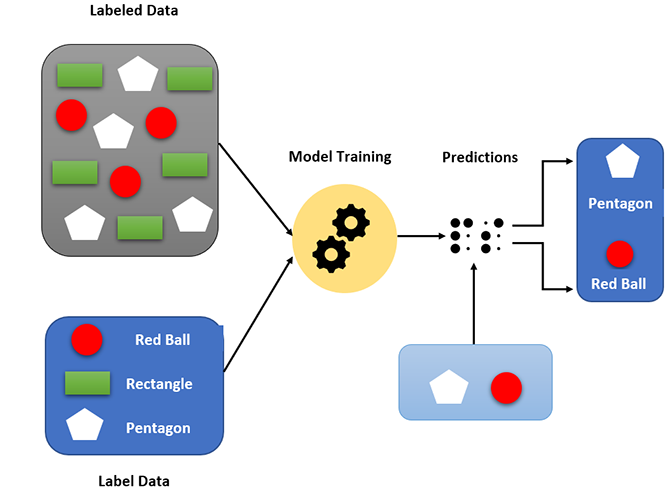
First, we have to make sample data from the dataset called training data to train the model. In our case, we are extracting the objects of round, rectangle, and pentagon into train data
Then we train the model for the data as
Now the model trained using the train data and then we provide the new data (new objects) to the model so that the model can easily classify them according to the trained data(color and number of sides) and predict the output.
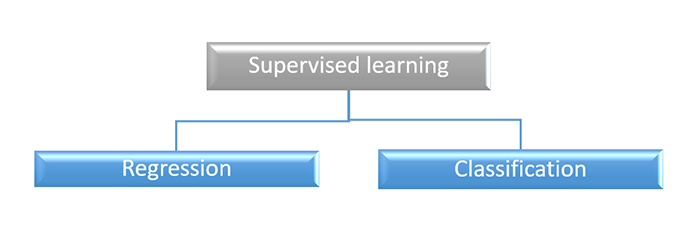
Supervised machine learning algorithms can be further divided into two depends upon the task we have to complete with the algorithm. that are
Regression algorithm is used for weather forecast, stock predictions, etc because regression algorithm needs a relation between the input and output variables. In regression, the output must be a real value and it predicts only a single output using the train data.
For example, if you want to predict a stock value and the input will be many factors like company data, performance, etc. but the output will be some real single value of stock amount.
There are many algorithms that work under the regression. Some of them are,
As the name suggests, this algorithm is used to classify or categorize the given dataset into different classes. This means it is used when the output has some categorical data in it.
If the data is classified into only two types, For example, classify as men and woman, true or false, animal or bird-like that it is called binary classification.
If it classified into more than two classes then it is multiclass. For example, we have to classify fruits into different classes. There are many algorithms that work under classification and they are

