

Many people think of machine learning only as a specific algorithm, such as logistic regression or random forests. However, in practice, many other components will determine the performance of a model. These steps include data cleaning and optimizing the model using hyper-parameter tuning.
Machine learning workflow defines the steps or the path that has to follow to make a machine learning project which includes,
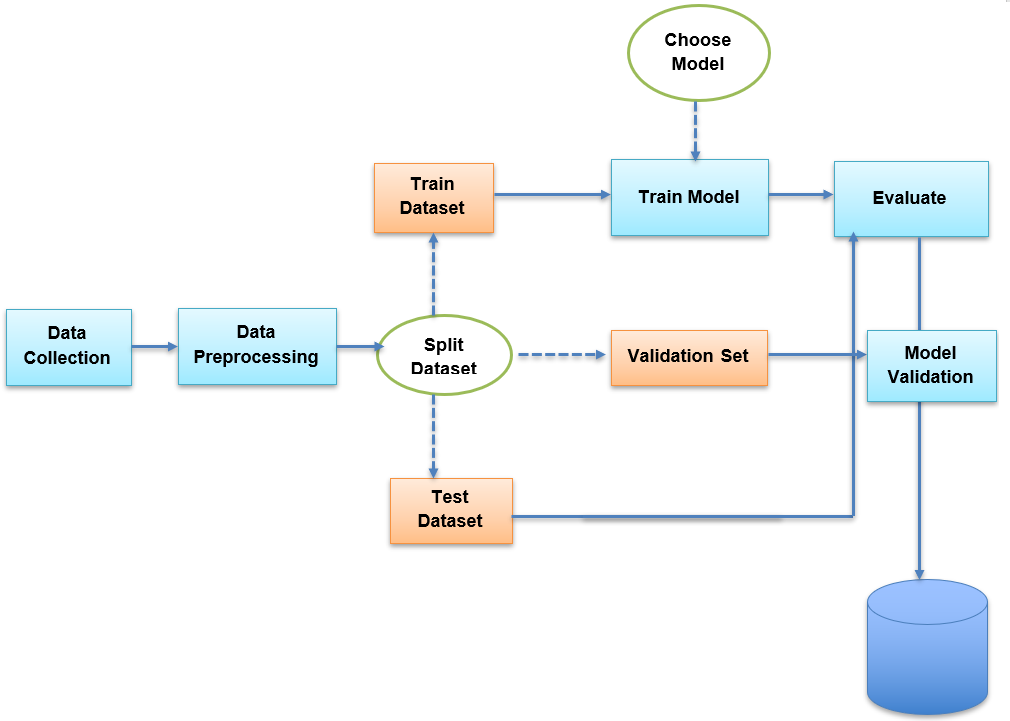
This tutorial covers each component of the machine learning workflow in more detail.
In this step, we have to collect the data from different sources, which may be the files or databases or the sensors, etc. If we are collecting real-time data, we can use the data from the IoT devices directly. The quality of the data received is very important for the accuracy of the system and the results.
Data that we collected from the files, scanners, etc, cannot be used directly as that will have a lot of unclarity, large values, and a lot of errors, and missing data will be there. For that, we have to do the data preparation.
Hopefully, someone out there has generated a dataset that you can use to answer your specific problem. Otherwise, we need to create our own dataset to funnel into the machine learning workflow. This can be the most labor-intensive, time-consuming, and expensive part of the machine learning workflow.
Once we have made our dataset, we need to create a datastore that allows us to access the data for later steps. An important point to take away is that we should keep a record of the original data set. This is essential for transparency and reproducibility.
Once we load the data, we should "clean up" the data. Data we got from the outside world will contain
that cannot be applied directly to the system. We have to clean that raw data into clean data sets using different methods which is commonly known as data preprocessing.
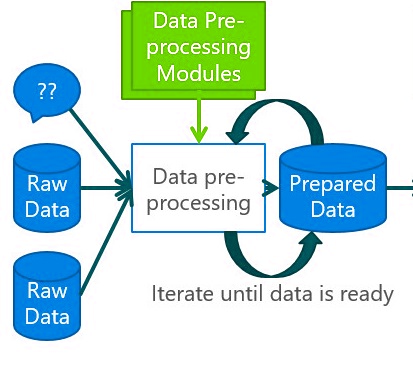
Data preprocessing is done through different steps that include
This is a complex but essential step in the machine learning workflow. Without understanding the underlying data structure, we may not be able to understand the model outputs.
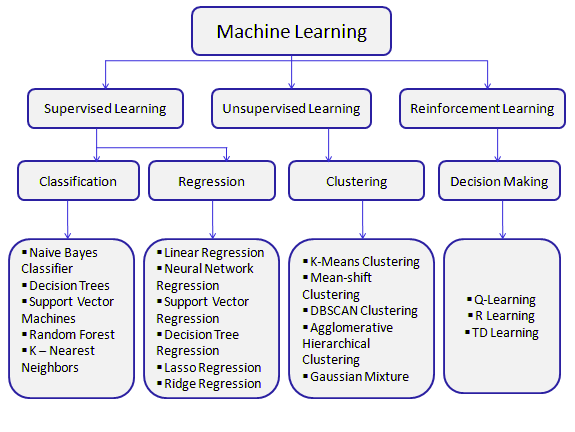
We already know from our previous tutorial that we have different models for the preprocessed data that we have to select for the best performance depending on the type of our goal and the type of data we had provided.
If the data is labeled and we have to classify the data we will use our classification algorithms. If we need a regression job and the provided data is a labeled one we can use the regression-learning model. If our data is unlabeled, we can use clustering models to make clusters for given data.
Finally, once we process the data, we need to split it into three datasets for training and to evaluate the machine-learning model we are using in the training phase to increase the ability of the model. To do the training we have to split the dataset:
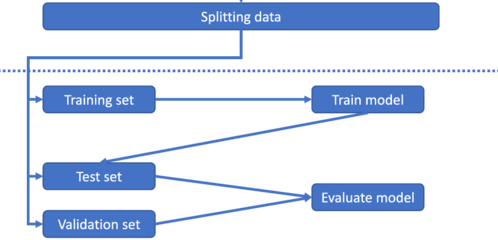
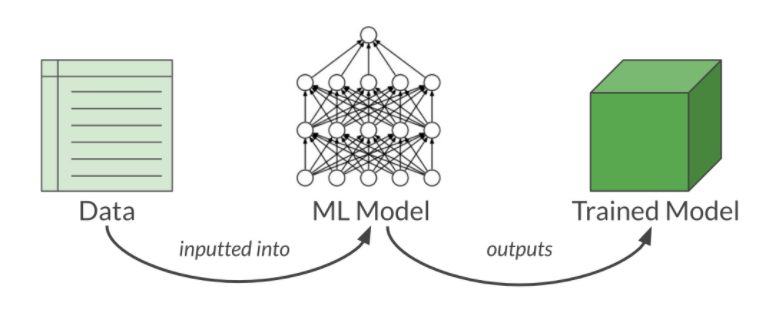
Once the data set is ready, we have to feed that training dataset into the model so that it can learn about the features and parameters. Now we can use the validation set for further refining the model by modifying the parameter up to your acceptable levels. The test set is used for testing the model.
In this phase, the learning algorithm finds a relationship between the input data and the output and generates a model.
Up until this point, we have been discussing ways to optimize the data for improving model performance. However, we can consider model components to optimize as well.
In this stage, the model is tested with test data set for accuracy and precision. We are using the test dataset because it is not used before training, which is fresh and gives a perfect result.
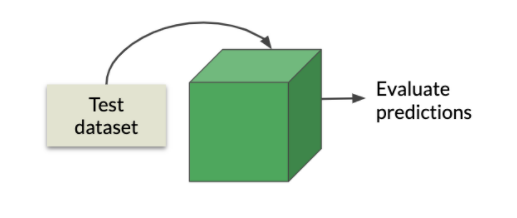
If the model is not performing well up to our expectations, we can rebuild the model using a more complex parameter called hyperparameters. Hyperparameter values control the learning process. Depending on the type of algorithm used, there can be many hyperparameters.
To choose a final model, we need to test the impact of each hyperparameter on model performance. This occurs during the model training process.
Once we determine appropriate model hyperparameters, we can evaluate the model using the test set. We can see if we need to continue tweaking our data/model during this phase or deploy the model as a product.
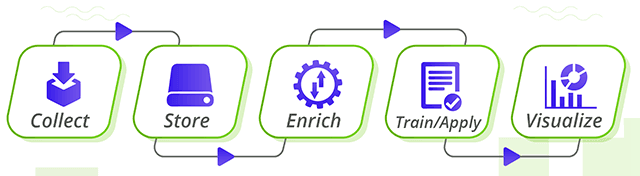
A machine learning pipeline is an automated way to execute the entire machine learning workflow. A pipeline adheres to essential software engineering principles. In a pipeline, we make workflow parts into independent, reusable, and modular components. This enables the process of building a model to be more efficient and simplified.

