

Now we have an understanding of the supervised learning methods and the different regression and classification algorithms that we use in supervised learning. Now it’s time to move further to non-managed learning which we call unsupervised learning.
In simple words, unsupervised learning helps to solve more real-world problems as it works similar to a human brain as it has to learn from the dataset regarding the underlying patterns without having a properly built training dataset.

Unsupervised learning is another type of machine learning. The goal is to learn the underlying patterns and structures within the data, without human intervention - without mapping it to a response variable or label. Instead, the data can be ranked, compressed, clustered, or visualized, allowing the user to understand a high-level overview of the entire dataset.
In other words, we can define unsupervised learning as the learning is done without supervision. That means we have a dataset only and there will not be a given training dataset for training the model. So the model has to find the internal patterns and relations hidden inside the dataset and classify them according to the similarities.
For a clear understanding, we can take an example of a set of vegetables and fruits. The unsupervised machine learning algorithm has to classify the pictures of vegetables and fruits. The difference is there is a trained dataset to know the features of vegetables and fruits to classify them like in supervised learning. Here the algorithm knows nothing about the features of vegetables or fruits; it has to identify the similarities in the images by itself and has to classify the given dataset into fruits and vegetables.
Unsupervised learning is doing that by clustering the images into groups according to the similarities it gets from analyzing the dataset.
Data exploration
Sometimes, we’re given a dataset, and we don’t have any directions on what kind of analysis to perform. Instead, we’re asked to look for interesting properties within the data.
This is what unsupervised learning is helpful for - understanding the data structure as it is, without any self-imposed biases. For example, by clustering the data, we can see if there are naturally emerging patterns that we can analyze further.
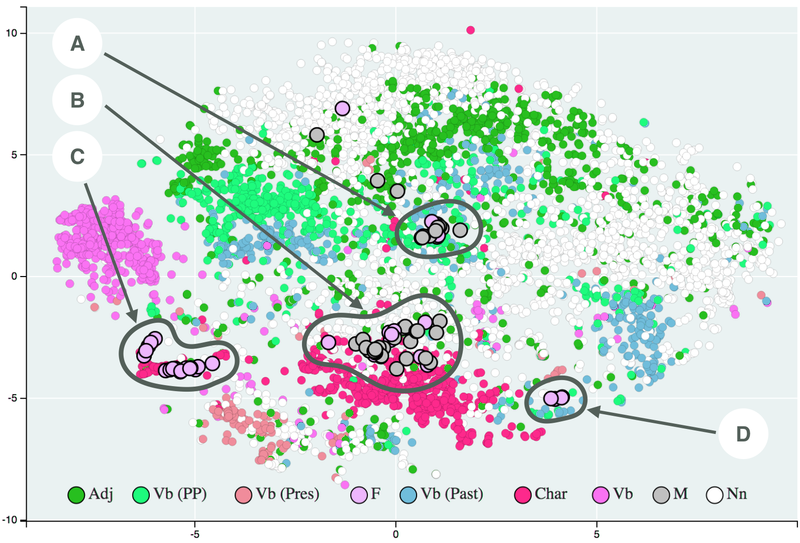
With a data set containing many features, it can be challenging to extract insights without a way to visualize the data within these high-dimensional datasets.
Some modern unsupervised learning algorithms like T-SNE and UMAP can compress a high-dimensional dataset into a smaller set. These methods make it easier to visualize the data while providing important insights into the underlying data structure.
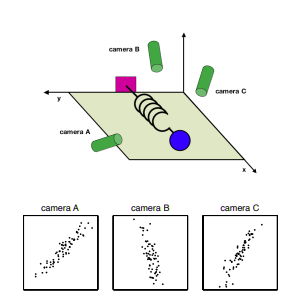
Let’s take the example from viewing a spring oscillating to measure the spring constant - a classic physics problem. We provide three cameras that are calculating the trajectory of the ball on the spring.
One question that comes up is, “are we viewing the data in the best direction to measure our spring constant?” (the answer is no). This is analogous to training a machine learning model, where we need to frame our data in the best way so that the model can extract as much information as possible. Unsupervised methods such as Principal Component Analysis can do that by decorrelating the data.
If we consider the camera example above, we notice three cameras all measuring the same event, just viewing the spring in a slightly different way. Thus, some of these features are a bit redundant.
Unsupervised learning methods can tell us which features don’t carry much information or are highly correlated with each other, allowing the model to learn more efficiently.
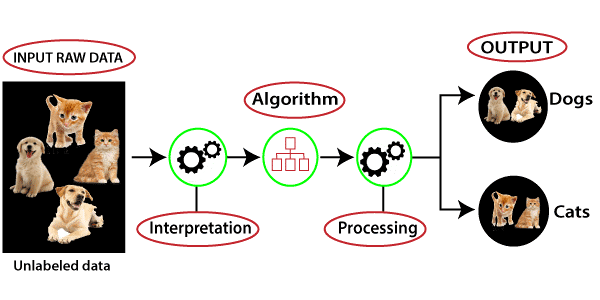
In this picture, we can understand that there is some raw data that has many items that are unsorted and uncategorized which are fed into the machine learning algorithm. It does not have any training dataset or output that helps to sort the data like in supervised learning.
Firstly, the machine-learning algorithm interprets the given dataset by itself to understand the hidden patterns inside the dataset, and then it sorts the dataset using the patterns.
There are many algorithms, which are able to work with unsupervised algorithms. When we apply the proper algorithm like k means clustering or decision tree, etc. then it groups the data into categories according to the patterns it finds from the dataset.
Clustering methods aim to group data based on similarities or differences to other data within the same set. We’ve seen an example of K-means clustering in the context of classification, where data points are grouped based on a centroid. There are many other methods to group data, such as hierarchical clustering and DBSCAN.
Association rule is a method that helps to find some relations between the variables in a given large dataset. It helps to find the set of data that occurs combined in a dataset.

You can imagine that you’re in a grocery store, and you’re trying to find some milk. You know from experience that milk is in the refrigerator aisle without explicitly being told it’s there. Additionally, because you’re buying milk, there is a high probability that you’re in the store to buy something to go with that milk, like cereal.
This buying experience is an example of association rules that aim to find relationships between variables within a given dataset based on probabilities.
Dimensionality reduction aims to reduce the number of features within a dataset and compress it so that only the most meaningful features remain. The principal component analysis is one method to reduce the number of features in a dataset.
When using unsupervised learning we have some advantages we listed below
While unsupervised learning can be a great way to model and understand your data, there are some challenges to be aware of:

